Von der grauen Theorie der Datenkomprimierung mit Hilfe des Huffman-Optimalcodes kommen wir jetzt zur Praxis« Anhand eines kleinen Programms entwickeln wir eine praktische Anwendung, die uns die Suche nach dem Optimalcode erleichtert.
Auf der TOS-Diskette finden Sie das in Turbo C geschriebene Programm »HUFFMAN.TOS« (mit dem zugehörigen Quelltext »HUFFMAN.C«), das Sie zunächst per Doppelklick starten. Das Demoprogramm erzeugt für maximal 16 Zeichen Huffman-optimale Codewörter. Nach dem Programmstart legen Sie zunächst die Zahl der verschiedenen Zeichen (zwei bis 16) fest und geben deren absolute Häufigkeit an. Nach kurzer Rechenzeit erscheint auf dem Bildschirm eine Liste mit den relativen Wahrscheinlichkeiten, den Huffman-Codierungen und den Codewortlängen. Weiterhin gibt das Programm die Codewortgröße ohne Verwendung des Huffman-Verfahrens, die durchschnittliche Codewortgröße im Huffman-Code und den Speicherbedarf für beide Codes an.
Betrachten wir nun den Quelltext des Programms. Besonders wichtig ist die Datenstruktur »satz«. In ihr legt das Programm die modifizierten Zeichen während der Codeerzeugung ab. Für diesen Zweck führen wir die Feldvariable »struct elemente[16]« ein, die ebenso viele Einträge umfaßt. Die Struktur enthält neben dem unsigned long-Element »haeufigkeit« (absolute Häufigkeit des Codewortes) das unsigned-Element »zugehoerigkeit«. Dieses legt die Zugehörigkeit des modifizierten Zeichens zu den ursprünglichen Zeichen fest, wobei Bit n das Zeichen n repräsentiert. Sind beispielsweise die Bits 1, 5 und 14 gesetzt, gehört das modifizierte Zeichen zu den ursprünglichen Zeichen 1, 5 und 14. Da es in C keinen direkten Zugriff auf die einzelnen Bits eines Datenwortes gibt, enthält unser Huffman-Programm die Funktion »bitO«, der wir stets die Bitnummer n übergeben. Als Ergebnis erhalten wir einen unsigned-Wert, bei dem lediglich Bit n gesetzt ist. Dies erreichen wir durch n-maliges Linksrotieren des Werts 1 (1 < n). Nach dem Programmstart ruft die Hauptfunktion »mainO« zunächst die Funktion »vorbereitungenO« auf, diedaschar-Feld »codewort[16][80]« löscht. In diesem 16 Elemente großen Zeichenketten-Feld bauen wir später die Huffman-Codewörter im ASCII-Format auf.
In »zeichenzahl« merken wir uns die Anzahl der zu codierenden Zeichen (2 bis 16). Die Variable »listengröße« gibt die Größe der Liste zur Codeerzeugung an. »struct satz« enthält im Element »haeufigkeit« die Häufigkeiten der Zeichen. Gleichzeitig setzen wir jeweils im Element »zugehoerigkeit« das der Eintragsnummer entsprechende Bit, zum Beispiel Bit 15 für Eintrag 15.
Als letzte Vorbereitungen führen wir einige statistische Operationen durch. Zunächst berechnet das Programm, wieviele Zeichen die gesamten Daten umfassen. Diesen Wert, den wir einfach durch Addition der jeweiligen Häufigkeiten ermitteln, speichern wir in »datenumfang«. Wie im ersten Teil beschrieben folgt die Berechnung der relativen Wahrscheinlichkeiten. Dazu dividieren wir die absolute Häufigkeit eines Zeichens durch die Gesamtzahl aller Zeichen (»häufigkeit«/»datenumfang«). An diesem Punkt vereinfacht sich das Programm: Aufgrund der gerade genannten Formel ist die absolute Wahrscheinlichkeit direkt proportional zur relativen. Da das Rechnen mit Ganzzahlen einfacher und schneller ist, arbeitet unser Programm mit den absoluten Wahrscheinlichkeiten.
Zur Codeerzeugung verzweigt die »main()«-Funktion in die »huffman()«-Funktion. Diese ruft solange die »reduktion()«-Funktion auf, bis die letzte Codereduktion und Zuweisung der Codestellen durchgeführt ist, also der Zähler »listengroesse« nicht mehr größer als 1 ist. Die »reduktion()«-Funktion arbeitet nach dem in der letzten Ausgabe besprochenen Codierungsschema. Zunächst sortieren wir die Liste mit den Zeichen und den zugehörigen absoluten Häufigkeiten nach abfallender Wahrscheinlichkeit. Glücklicherweise bietet die Turbo-C-Bibliothek die »qsort()«-Funktion an, über die Sie näheres der Fachliteratur entnehmen. Der zweite Schritt ist die Zuweisung der Codewortstellen »0« und »1« zu den letzten beiden Zeichen der Liste. Alle ursprünglichen Zeichen durchlaufen wir in einer for-Schleife. In dieser testen wir zunächst für das vorletzte Element der Tabelle, ob es das aktuelle ursprüngliche Zeichen repräsentiert. Dazu führen wir einfach eine Und-Verknüpfung zwischen der »zugehoerigkeit«-Variablen und dem entsprechenden Bit durch. Ist das Ergebnis ungleich Null, ist das Bit gesetzt und das ursprüngliche Zeichen wird durch das Element repräsentiert. Dazu stellen wir mit Hilfe der »strcpy()«- und »strcat()«-Funktionen eine Null vor den bisherigen Code des Zeichens »codewort[zeichen]«. ln einem zweiten Schritt wiederholen wir den gleichen Vorgang für das letzte Element der Tabelle, wobei wir gegebenenfalls eine 1 an den Anfang des Codes stellen.
Als nächsten Schritt führen wir bei Tabellen mit mehr als zwei Einträgen eine Reduktion durch, wobei wir die letzten zwei Zeichen der Liste (mit den niedrigsten Häufigkeiten) zusammenfassen und deren absolute Wahrscheinlichkeiten addieren. Außerdem führen wir eine »oder«-Verknüpfung der Zuordnungs-Einträge »zugehoerigkeit« durch. Waren beim vorletzten Eintrag die Bits 2 und 13 sowie beim letzten Eintrag die Bits 7, 9 und 15 gesetzt, so sind es nun für den gemeinsamen Eintrag die Bits 2, 7, 9, 13 und 15. Vor dem Rücksprung aus der »reduktion()«-Funktion inkrementiert diese den Zähler »listengroesse«. Die Funktion »statistik()« ermittelt die Wortgröße sowie den zu erwartenden Speicherbedarf für die Gesamtinformation mit und ohne Huffman-Codierung. Dazu multiplizieren wir die Codewortgröße mit der Anzahl der Zeichen. Zuletzt kümmert sich die »ausgabe()«-Funktion um die Ausgabe der Codes, der Codewortgrößen sowie des Speicherbedarfs.
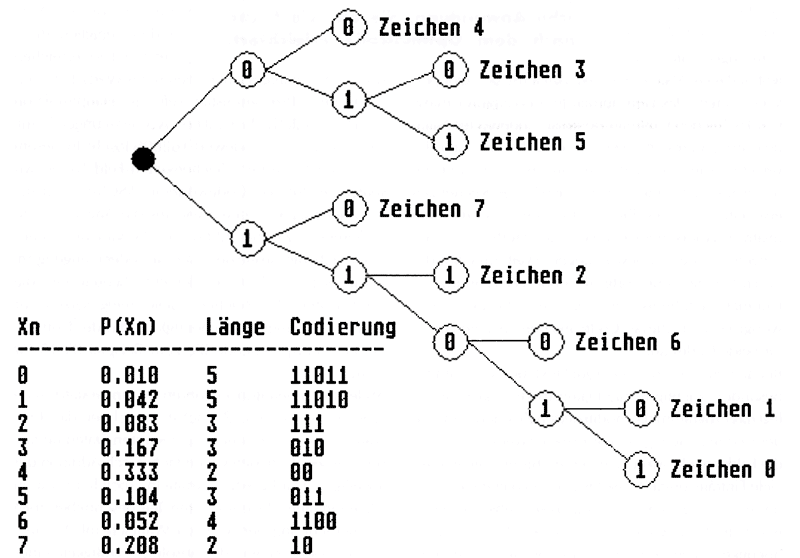 Bild 1. Folgen Sie den Verzweigungen der Baumstruktur, erhalten Sie die entsprechenden »optimalen« Codeworte
Bild 1. Folgen Sie den Verzweigungen der Baumstruktur, erhalten Sie die entsprechenden »optimalen« Codeworte
 Bild 2. Unterschiedlich lange Bitfolgen repräsentieren die Daten in komprimierter Form
Bild 2. Unterschiedlich lange Bitfolgen repräsentieren die Daten in komprimierter Form
In Bild 1 sehen Sie eine Codierung für acht Zeichen in Tabellenform und als Baum. Bei letzterem ist auffällig, daß von jedem Knoten maximal zwei Zweige ausgehen, da es sich um einen binären Code handelt. Zum Ermitteln des Codes eines Zeichens durchlaufen Sie einfach alle Zweige von der Wurzel bis zum Endknoten (dem Blatt) mit dem betrachteten Zeichen.
Unser Beispielprogramm demonstriert anschaulich die Erzeugung eines Huffman-Optimalcodes für maximal 16 Zeichen. Möchten wir jedoch eine Datei aus einer Folge von jeweils 8 Bit (1 Byte) großen Zeichen komprimieren, so müssen wir für 256 Zeichen den optimalen Code erzeugen. Ein solches Komprimierungsprogramm hat also zunächst die gesamte Datei Zeichen für Zeichen zu durchkämmen und gleichzeitig die absoluten Häufigkeiten der 256 Zeichen zu bestimmen. Soll unser Algorithmus 256 Zeichen codieren, muß die Anzahl der Zugehörigkeits-Bits ebenfalls 256 betragen. Zudem ist der Teil der Codestellen-Zuweisung so zu modifizieren, daß der Code anschließend in binärer Form vorliegt. Nun erzeugen wir eine komprimierte, nicht mehr direkt lesbare Datei. Die einzelnen Codewörter haben in dieser eine variable Größe, weshalb wir nicht Byte-, sondern Bitfolgen hintereinander speichern. Liegt beispielsweise der Code aus Bild 1 vor, so ist für die Zeichenfolge 4, 6,0, 7, 3, 2, 7, 2, 7, 3, 6 und 4 die Bitfolge 001100110111 00101111011110010110000 in der Datei abzulegen (siehe Bild 2). Doch mit Codieren und Ablegen der alten Information ist es noch nicht getan. Zum späteren Dekomprimieren der Daten müssen Sie die verwendeten Codewörter aller 256 Zeichen in der Datei ablegen. Diese Tabelle verschlingt eine Menge Platz, weshalb die Datenkomprimierung erst ab einer bestimmten Größe der Ursprungsdatei interessant ist. Ist die komprimierte Datei an den Empfänger gelangt, so möchte dieser aus dem unbrauchbaren Archiv verwendbares Datenmaterial herstellen, also die Datei dekomprimieren. Hierfür liest das Dekomprimierprogramm zunächst die Tabelle der verwendeten Codewörter ein. Anschließend erfolgt die Dekomprimierung, wobei für jedes zu dekomprimierende Wort die möglichen Codewörter mit den ersten Bits der Datei zu vergleichen sind, bis eine Übereinstimmung vorliegt. Ist dies der Fall, so schreibt das Programm das entsprechende Byte-Zeichen in die neue, dekomprimierte Datei und setzt den Dateipositionszeiger neu. Mit diesen Kenntnissen sind Sie nun selbst in der Lage, Ihre Programme mit einem Komprimierverfahren auszustatten. (ah)