Alle TOS-Rechner verwenden DRAM. Erst die kommende Centurbo 060-Karte geht hier einen anderen Weg. Matthias Alles erklärt die DRAM-Technologie im Detail.
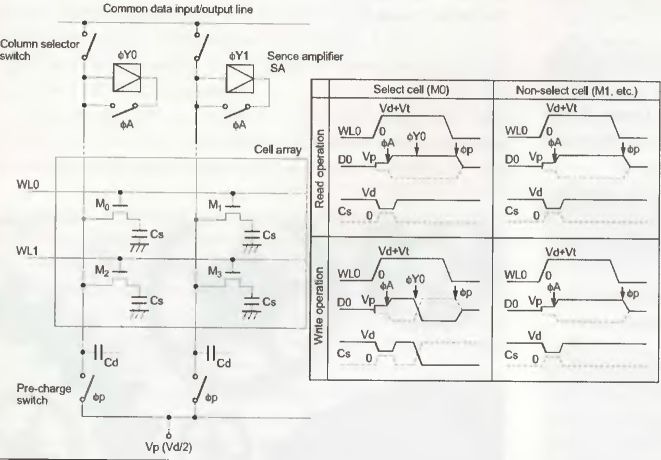 Dieser kleine Ausschnitt aus einer Speichermatrix verdeutlicht den im Grunde recht einfachen Aufbau der DRAMs.
Dieser kleine Ausschnitt aus einer Speichermatrix verdeutlicht den im Grunde recht einfachen Aufbau der DRAMs.
DRAM (Dynamic Random Access Memory) ist aus heutigen Computern nicht wegzudenken. Auf Grund des stets relativ guten Preis/Leistungsverhältnisses, hat diese Speichergattung ohne Zweifel zu der massiven Verbreitung von Computern beigetragen. Aber die Nachteile lassen sich nicht verleugnen: Der geringe Preis resultiert aus einem einfachen Aufbau, der sich in einer verminderten Geschwindigkeit ausdrückt. Da sich am Grundprinzip des DRAM allerdings seit Jahrzehnten nichts geändert hat, ist es um so erstaunlicher, dass es dennoch in heutigen Computern Verwendung findet. Um jedoch gewisse Eigenschaften von DRAMs verstehen zu können, ist ein Blick ins Innere der Speicherchips vonnöten.
Bitte ein Bit
Moderne DRAMs benötigen zur Speicherung von einem Bit lediglich einen Transistor und einen Kondensator. Gespeichert wird die Information in dem wenige fF großen Kondensator, der entweder mit OV für logisch 0 oder bspw. 5V für logisch 1 geladen ist (1 femto Farad = 10-15 F). Die in diesem Fall vorliegende 1-Transistor-Zelle ermöglicht es, einen hohen Integrationsgrad auf dem Die zu erreichen, womit die Kosten eines Speicherchips deutlich reduziert werden können. Statische RAMs (SRAM) hingegen, die u.a. bei Cache-Speicher zum Einsatz kommen, haben zwar schnellere Zugriffszeiten, benötigen zur Speicherung eines Bits aber auch sechs Transistoren, was diese auf Grund des hohen Platzbedarfs wiederum teurer macht. Nun kann man mit einem Bit nicht allzu viel anfangen, weshalb eine Vielzahl von 1-Transistor-Zellen in einer Matrix angeordnet werden. Eine komplette Zeile dieser Matrix bezeichnet man als Page, also Seite. Zur Adressierung eines Bits benötigt man sowohl eine Zeilen- (Row), als auch eine Spaltenadresse (Column). Diese werden dem Speicherchip an der gemultiplexten Adressleitung mittels /RAS- und /CAS-Signalen übermittelt, doch dazu später mehr.
Um ein Bit auszulesen, geschieht nun folgendes: Zunächst muss ein sogenanntes Precharge (vorher laden) ausgeführt werden. Dabei werden alle Datenleitungen mit der halben Spannung für logisch 1 geladen, also beispielsweise 2.5V wenn der Chip mit 5V arbeitet. Die hierfür benötigte Zeit heißt Precharge-Time. Währenddessen wertet der Zeilendekoder im Speicherchip die Zeilenadresse aus und selektiert nach dem Precharge die passende Wordline (WL) mit einem Spannungsimpuls. Sämtliche Transistoren dieser Page leiten nun. Der geladene Kondensator sorgt jetzt dafür, dass sich die Spannung auf der Dataline leicht ändert, je nach Ladezustand also leicht kleiner oder leicht größer wird als die vorherigen 2.5V. Am Ende der Dataline kommt nun der Sense Amplifier zum Zuge. Dieser nutzt die Precharge-Spannung als Referenzspannung und wandelt die dazu negativere Spannung in 0V und die dazu positivere Spannung in 5V um. Je nach Spaltenadresse wird der Inhalt der gewählten Speicherzelle nach außen ausgegeben. Jetzt besteht allerdings das Problem, dass sich alle Kondensatoren einer Page entladen haben, und somit deren Inhalt zerstört wurde. Als Konsequenz müssen all diese Speicherzellen wieder beschrieben werden. Also sorgen die Sense Amplifier nach dem Lesen dafür, dass auf sämtlichen Datenleitungen die ausgewertete Information wieder als 0V bzw. 5V vorzufinden ist. Der Kondensator lädt sich schließlich mit dieser Spannung auf und hat somit wieder die korrekte Information gespeichert. Um ein Bit zu schreiben, muss man genau so vorgehen, wie beim Lesen. Nur werden hier nach dem Lesen der Page keine Daten nach außen weitergeleitet, sondern von außen gelesen, um sie anschließend auf die selektierte Dataline weiterzuleiten. Würde man vor dem Schreiben eines Bits nicht die ganze Page auslesen, so ist klar, dass dann bis auf das eine geschriebene Bit alle anderen Informationen in der Page verloren gingen. Bei einem Lese- bzw. Schreibzugriff werden also immer alle Speicherzellen einer Page gelesen und wieder zurückgeschrieben, auch wenn sie nicht benötigt werden.
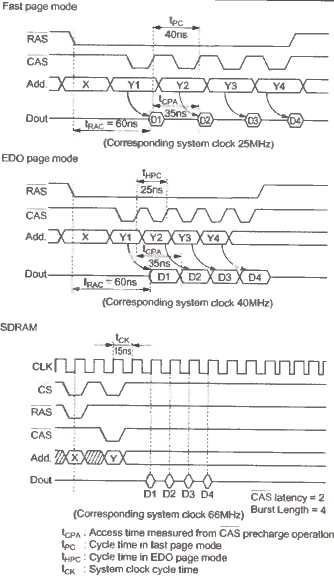 Speicherarten im Vergleich: Durch verfeinerte Verfahren lassen sich höhere Speicherdurchsätze erzielen.
Speicherarten im Vergleich: Durch verfeinerte Verfahren lassen sich höhere Speicherdurchsätze erzielen.
Speicherchips, die beispielsweise 4 Bits gleichzeitig ausgeben können, verfügen lediglich über vier parallel arbeitende Matrizen. Wie die Matrix organisiert ist, hat direkte Auswirkungen auf den Stromverbrauch des Chips: Je mehr Spalten dieser hat, desto mehr Kondensatoren müssen auch bei jedem Lese- bzw. Schreibzugriff neu geladen werden. Eine höhere Stromaufnahme ist die Folge. Es haben sich mittlerweile eine Vielzahl von Speicherchips etabliert, die häufig eine unterschiedliche Organisation haben. Ein 16Mbit-Chip kann beispielsweise als eine 40964096 oder 163841024 Matrix organisiert sein. Beim ersten Beispiel spricht man von einen 12/12-Mapping (2A122A12= 2A24=16.777.216), während das zweite Beispiel einem 14/10-Mapping (2A142 A10=2A24=16.777.216) entsprechen würde. Vier solcher Speicherfelder würden aus dem Chip schließlich ein 64Mbit-Chip machen, der als 16 MBit x 4 organisiert wäre. Am Mapping ist abzulesen, aus wieviel Adressbus die Zeilenadresse und aus wie vielen Adressbus die Spaltenadresse bestehen muss. Ein asymmetrisches 14/10-Mapping erfordert 14 Adressbits für die Zeilen (2A14=16384) und 10 Adressbits (2A10=1024) für die Spalten. Um Leitungen zu sparen, bekommt der Speicherchip nur so viel Pins zur Adressierung, wie unbedingt nötigt, also in diesem Fall 14. Zur Adressierung einer Speicherzelle wird diese Adressierung also gemulti-plext, d.h. dass die Daten nacheinander übermittelt werden. Zunächst wird die Page-Adresse mittels aktiviertem /RAS-Signal (Row Adress Strobe) übertragen und anschließend die Spaltenadresse mittels aktiviertem /CAS-Signal (Column Adress Strobe).
Das ist das Grundprinzip von dynamischen Speichern. Der Speicherdurchsatz scheint daher zunächst äusserst gering, da für jeden Lese- bzw. Schreibzugriff Zeilen- und Spaltenadresse an den Speicherchip angelegt werden müssen.
Von taktlosen Speichern... Schon früh wurden sich daher Gedanken gemacht, wie denn der Speicherdurchsatz zu erhöhen sei, um nicht die Recheneinheiten verhungern lassen zu müssen. Betrachtet man den Code von Prozessoren im RAM, so fällt schnell auf, dass dieser meist sequentiell gespeichert ist. Als Konsequenz liegen die von der CPU geforderten Daten häufig in einer Page, was es unnötig macht, jedesmal die Page-Adresse mit dem /RAS-Signal zu übermitteln. Statt dessen wird diese nur einmal übermittelt und im RAM-Chip gespeichert. Die Speicherlogik hält dabei das /RAS-Signal aktiv. Der Speicherchip weiß dann, dass jetzt schnelle Zugriffe auf das RAM folgen. Synchron mit dem /CAS-Signal für die Spaltenadressierung erhält der Speicherchip jetzt nur noch die Spaltenadresse, wodurch bei diesen sogenannten Burst-Zugriffen eine Menge Zeit gespart werden kann. So arbeitende DRAMs tragen den Namen Page Mode DRAMs, da sie bei einem Page Hit schneller Daten liefern können.
Die nächste logische Konsequenz ist, dass die Lese- und Schreibverstärker nicht nach jedem Zugriff auf die Speichermatrix die gerade gelesenen Daten wieder zurückschreiben, sondern erst beim Wechsel der Page. Dadurch entfällt im Burstmodus die RAS-Precharge-Time womit sich die CAS-Zykluszeit verringert. Die so optimierten Page Mode DRAMs sind als Fast Page Mode DRAMs (FPM-DRAM) bekannt und kamen beispielsweise im TT und Falcon zum Einsatz. FPM-DRAMs haben aber weiterhin den Nachteil, dass das /CAS-Signal angibt, wie lange ein Lesezyklus dauert. Dadurch hat man nicht die Möglichkeit bereits die Spaltenadresse des darauffolgenden Zugriffs zu übergeben. Dies kann erst geschehen, wenn die Daten auf dem Datenbus zurückgeschrieben wurden. Und genau bei diesem Punkt setzen EDO-DRAMs (Extended Data Out) an. Hier übernimmt das /OE-Signal die Aufgabe, das Ende eines Lesezyklus anzuzeigen. Mit dem /CAS-Signal kann daher bereits die nächste Adresse übertragen werden, während auf der Datenleitung noch das zuvor ausgelesene Datum zu finden ist. Durch dieses leichte Paralleli-sieren des Zugriffs (Overlap), ist es möglich, die CAS-Zykluszeit bei 60ns-DRAMs von 40ns bei FPM-DRAMs auf 25ns bei EDO-DRAMs zu verkürzen. Hieraus resultierend kann ein EDO-DRAM bei Burst-Zugriffen und einem Bustakt von 40MHz jeden Takt Daten liefern, während ein FPM-DRAM dies nur bei 25 MHz schafft. Es sei jedoch angemerkt, dass die Beschleunigung von EDO gegenüber FPM nur beim Lesen gilt. Beim Schreiben jedoch ist ein Overlap nicht möglich. Die Weiterentwicklung von EDO-DRAMs trägt die Bezeichnung BEDO (Burst Extended Data Out). Da die angeforderten Daten meistens sowohl in einer Page als auch direkt aufeinanderfolgend in einer Zeile liegen, überlässt man BEDO-DRAMs, nachdem man die Spalten- und Zeilenadresse angelegt hat, sich selbst. Der Speicherchip generiert sich intern die neuen Spaltenadressen durch einen Adressgenerator und liefert die geforderten Daten synchron zum /CAS-Signal, wodurch eine erneute Verringerung der CAS-Zykluszeit ermöglicht wird. Somit können BEDOs bei 66 MHz Bustakt mit einem 5-1-1-1 Burst dienen und sind damit den normalen EDOs deutlich überlegen. Doch trotz des guten Konzepts konnten sie sich - insbesondere wegen dem schnellen SDRAM - nie durchsetzen und waren demnach auch nur kurze Zeit am Markt vertreten.
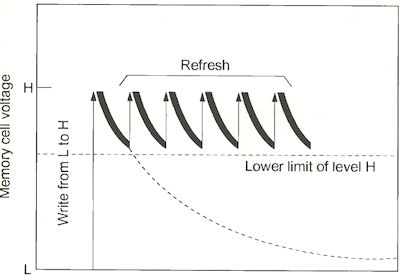 Leckströme sorgen dafür, dass sich die Kondensatoren entladen. Daher ist das Auffrischen des Speicherinhaltes unabdingbar.
Leckströme sorgen dafür, dass sich die Kondensatoren entladen. Daher ist das Auffrischen des Speicherinhaltes unabdingbar.
...und taktvollen Speichern. Eben diese SDRAMs (Syncronous DRAM) sind es, die die heutige Speicherszene dominieren. Vom Grundprinzip arbeitet diese Speichergattung genauso wie die oben vorgestellten Speichertypen. Jedoch ist SDRAM wesentlich flexibler und intelligenter als die Vorgänger. Alle Steuersignale hängen an einem Takt, der je nach Alter der SDRAMs 66, 100, 1 33 oder demnächst 166 MHz betragen kann. Die Steuersignale selbst (/CS, /RAS, /CAS, /WE) sind als eine Art Kommandogeber zu verstehen, die dem Speicher je nach Bitmuster genau mitteilen, was dieser zu tun hat. Das SDRAM speichert das anliegende Kommando bei steigender Taktflanke. Vom Aufbau her ist es so weit fortgeschritten, dass es nach dem Erhalt eines Kommando die ihm erteilte Aufgabe selbstständig erledigen kann, ohne dass es weiterer Steuersignale von außen bedürfte. Um die Speicher an die Anforderungen des Systems anzupassen, hat man sogar die Möglichkeit, gewisse Eigenschaften des Speicherchips mittels des Mode-Registers selbst festzulegen. Unter anderem kann hier bestimmt werden, aus wie vielen Speicherzugriffen ein Burst-Zugriff bestehen soll. So ist es möglich, dass dieser aus 1, 2, 4 oder B Zugriffen besteht, oder dass gleich die ganze Page ausgelesen wird. Der Lead-Off-Cycle (also das Lesen des ersten Datums bei einem Burst-Zugriff) dauert allerdings auch bei SDRAMs 5 Taktzyklen, wie bei den bisherigen Speichern. Anschließend sprudeln die Daten jedoch im Systemtakt zur oder von der Außenwelt. Auf Wunsch kann ein Burst auch abgebrochen oder nur eingefroren werden, wenn er nach einer Weile wieder fortgesetzt werden soll. Die CAS-Latency, die ebenfalls im Mode-Register einstellbar ist, gibt an, wieviele Takte nach dem Anlegen der Spaltenadresse der Speicher die ersten gültigen Daten liefern soll. Zu kaufen gibt es SDRAMs mit CL2 und welche mit CL3. Bereits am Preis ist erkennbar, dass DRAMs mit CL2 stets schneller sind, als welche mit einer CAS-Latency von nur 3.
Eine weitere Neuerung neben dem Taktsignal besteht darin, dass SDRAMs intern aus mindestens zwei Bänken aufgebaut sind, die sich unabhängig voneinander ansprechen lassen. Dadurch wird es möglich, gewisse Aktionen zu parallelisieren, die so den Speicher nicht mehr ausbremsen. Beispielsweise kann von der einen Bank gerade im Burstzugriff gelesen werden, während man auf der anderen Bank per Kommando bereits ein Precharge für den nächsten Zugriff ausführt. Auf diese Weise ist es aber auch möglich, die Precharge-Time bzw. die 5 Taktzyklen des Lead-Off-Cycles zu verbergen, indem die eine Bank bereits adressiert wird, während die andere noch Daten liefert.
Auf den Speichermodulen (DIMMs) findet sich aber neben den eigentlichen Speicherchips auch noch ein kleines EEPROM, das SPD-EEPROM (Serial Presence Detect). Dieses kann mittels l_C-Bus ausgelesen werden und enthält Informationen über die Speicherchips auf dem Modul, z.B. deren Organisation oder die Zugriffszeiten.
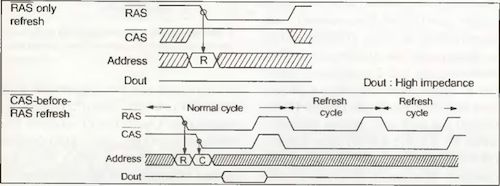 Zum Ausführen eines Refreshs benutzt man Signalkombinationen, die bei Lese- und Schreibzugriffen nicht möglich sind.
Zum Ausführen eines Refreshs benutzt man Signalkombinationen, die bei Lese- und Schreibzugriffen nicht möglich sind.
Nachdem wir nun die SDRAMs näher betrachtet haben, sind wir an der Spitze der derzeitigen Speicherentwicklung angelangt. Hier tummeln sich zum einen der recht teure RAMBUS-Speicher, der scheinbar in immer weniger Rechnern verwendet wird und auf den hier nicht weiter eingegangen werden soll. Bei dem anderen Speicher handelt es sich um eine Weiterentwicklung des SDRAMs, auch wenn die Änderungen nicht so gravierend sind. Das DDR-SDRAM (Double Data Rate), von dem die Rede ist, besticht dadurch, dass es doppelt so viele Daten liefern soll, wie die bisherigen SDRAMs. Bei DDR-SDRAM wird allerdings nicht - wie man vermuten könnte - einfach der Takt verdoppelt. Vielmehr werden nun zwei Aktionen bei einem Takt ausgeführt. Waren herkömmliche SDRAMs stets zur aufsteigenden Taktflanke des Bustaktes synchronisiert, so benutzt man bei diesem Speicher sowohl die aufsteigende als auch die fallende Taktflanke zur Daten- und Kommandoübermittlung.
Da der Speicher so auf recht wackeligen Beinen steht, hat man ihm zusätzlich ein bidirektionales Signal (DQS) zur Kontrolle spendiert. Gibt der Speicher Daten aus, zeigt dieser damit die Gültigkeit der Daten an, gibt der Chipsatz Daten aus, so steuert er das DQS-Signal.
Panta rhei - Alles fließt
Eine weitere Eigenschaft von DRAMs, die wir bisher ganz außer Acht gelassen haben, ist der Refresh. Wie zu Beginn des Artikels gesehen, werden die Informationen einer Speicherzelle in einem Kondensator gespeichert. Auf Grund von Leckströmen allerdings entlädt sich der Kondensator recht schnell wieder, ohne dass man dies unterbinden könnte. Genau diese Eigenschaft ist der Preis, den man für die hohe Packungsdichte des Speichers zahlen muss: Die Geschwindigkeit hat unter diesem Umstand sehr zu leiden.
Bei einem Refresh wird nun der Inhalt einer Page ausgelesen, um ihn anschließend wieder zurückzuschreiben. Natürlich muss diese Auffrischung geschehen, bevor die Spannung im Kondensator nicht mehr ausreicht, um die gespeicherte Information mittels Sense Amplifiers zu ermitteln. Die Zeit, die maximal zwischen zwei Refreshs des gleichen Kondensators vergehen darf, heißt Refresh Period. Da immer zeilenweise aufgefrischt wird, lässt sich aus der Anzahl der Zeilen ablesen, wie groß der Refresh Cycle sein muss, der angibt, wieviele Refreshs in der Refresh Period ausgeführt werden müssen. Chips mit 2A11=2048 Zeilen haben üblicherweise einen 2K Refresh, während Chips mit 4096 Zeilen einen 4K Refresh aufweisen. Ein Zeilen-Refresh-Zyklus, also die Zeit, die durchschnittlich für einen Zeilenrefresh benötigt wird, ist festgelegt auf 15,6ps. Bei einem 2K-Refresh ergibt sich damit eine Refresh Period von 32ms (204815,6ps=32ms), bei einem 4K-Refresh von 64ms (409615,6ps=64ms).
Auch hier gibt es mehrere Methoden, die den Refresh mehr oder weniger nicht zu sehr ins Gewicht fallen lassen sollen. Grob unterscheidet man drei Refresh-Arten:
- RAS only Refresh: Bei der Ansteuerung des DRAMs geht man zunächst so vor, wie bei einem Lesezugriff. Nur übermittelt man nach der Zeilenadresse keine Spaltenadresse mehr, lässt also das /CAS-Signal inaktiv. Das DRAM führt daraufhin in der angelegten Zeile ein Refresh durch.
- CAS before RAS Refresh: Bei einem gewöhnlichen Lese-/Schreibzugriff wird stets zuerst die Zeilenadresse mittels /RAS übermittelt. Wird allerdings zuerst das /CAS-Signal aktiviert, gibt /RAS die Dauer eines Refresh-Zyklus an. Die Zeilenadresse braucht hierbei nicht mehr übermittelt zu werden, da das DRAM für diesen Refresh über einen internen selbstinkrementierenden Adresszähler verfügt.
- Hidden Refresh: Dieser versteckte Refresh kommt heute eigentlich nicht mehr zum Einsatz, da hohe Busfrequenzen es kaum noch ermöglichen, diesen zu benutzen. Bleibt nach einem Lesezugriff /CAS aktiv, wird der Hid-den-Refresh ausgelöst, wenn noch ein weiterer /RAS-Impuls erfolgt. Auch hier beinhaltet das DRAM einen eigenen Zeilenadresszähler. Allerdings funktioniert der Hidden Refresh nur, wenn der nächste Zugriff auf das RAM hinter dem eigentlichen Refresh liegt, die Busfrequenz also gering genug ist, um den Refresh zwischen zwei Speicherzugriffen zu verstecken.
Bei SDRAMs bzw. DDR-SDRAMs hat man es da einfacher, da lediglich das Kommando für einen Refresh zu übermitteln ist, und man sich nicht um das Timing zwischen den einzelnen Steuersignalen zu kümmern braucht.
Zu guter letzt
Seit nunmehr 37 Jahren hat Moores Gesetz, nach dem eine Verdopplung der Leistungsfähigkeit von Prozessoren alle 18 bis 24 Monate eintritt, Gültigkeit. Bisweilen ist auch nicht absehbar, wann dem nicht mehr so sein wird. Was aber für Prozessoren gültig ist, trifft ebenso auf die Kapazität von Speicherchips zu. Performance und Größe gehorchen gleichermaßen Moores Gesetz und steigen demnach rasant an. Verbesserte Herstellungsprozesse, die höhere Packdichten und höhere Frequenzen ermöglichen, werden auch zukünftig verhindern, dass das Nadelöhr zwischen Prozessor und Speicher nicht allzu klein wird. Doch am Prinzip von DRAM wird sich auch in den nächsten Jahren nichts ändern.