
Augur - Automatische Schrifterkennung mit ST und Scanner
Texterfassung. Dieses schnöde Wort bedeutet im allgemeinen: Abtippen. Diese Art von Arbeit gehört natürlich nicht zu den allgemein als beliebt angesehenen Tätigkeiten. Aber es kündigen sich bessere Zeiten an: Der Computer lernt lesen. Zwar kann er nicht verstehen, was er liest, doch immerhin kann er in gewissen Grenzen die Buchstaben auf einer Vorlage erkennen und daraus einen Text erzeugen, den man in einer Textverarbeitung weiterverwenden kann. Abtippen ade.
Zwei Dinge braucht der Mann (die Frau), um in den Genuß derart ungewohnten Komforts zu kommen:
- einen Scanner, der Papier-Vorlagen in ein computerlesbares Bild umwandelt und
- ein Programm, das dieses computerlesbare Bild dann auf ‘Textgehalt' hin untersucht.
Augur ist das erste Programm dieser Art, das auf dem ST Schrifterkennung auf verhältnismäßig hohem Niveau ermöglicht. Es ist in einer ‘Gemeinschaftsproduktion' der Schweizer Firma Marvin und der ETH Zürich entstanden.
Nicht nur die Aufgabe von Augur ist ungewöhnlich, auch sein Lieferformat: Das ganze Programm wird auf einer winzigen ROM-Cartridge, die fast völlig im ROM-Slot verschwindet, geliefert. Das ist natürlich ungeheuer praktisch, da erstens kein Speicherplatz verschwendet wird und zweitens die Ladezeit extrem kurz (Praktisch nicht vorhanden) ist. Auch Sicherheitskopien sind nicht notwendig, ein Kopierschutz ebensowenig. Der Nachteil wird sich vermutlich bei eventuellen Updates zeigen: Die Produktion einer solchen Cartridge ist natürlich teurer als das Kopieren von Disketten.
Möglichkeiten
Augur kann im Prinzip Texte in beliebigen Schrifttypen, die auch nicht auf lateinische Alphabete beschränkt sein müssen, erkennen. Wichtigste Voraussetzung ist, daß die einzelnen Buchstaben voneinander deutlich abgesetzt sind; Prortionalschrift ist also überhaupt kein Problem, während Schreibschriften, die aus miteinander verbundenen Buchstaben bestehen, grundsätzlich nicht gelesen werden können. Es ist auch von großem Vorteil für die Schrifterkennung, wenn gleiche Buchstaben möglichst immer gleich aussehen. Die Erkennung von handgeschriebener Druckschrift ist deshalb problematisch. Die Schriftgröße muß, je nach Auflösung des Scanners, zwischen 1 mm und 4 mm (400 dpi) oder 2 mm und 8 mm (200 dpi) liegen.
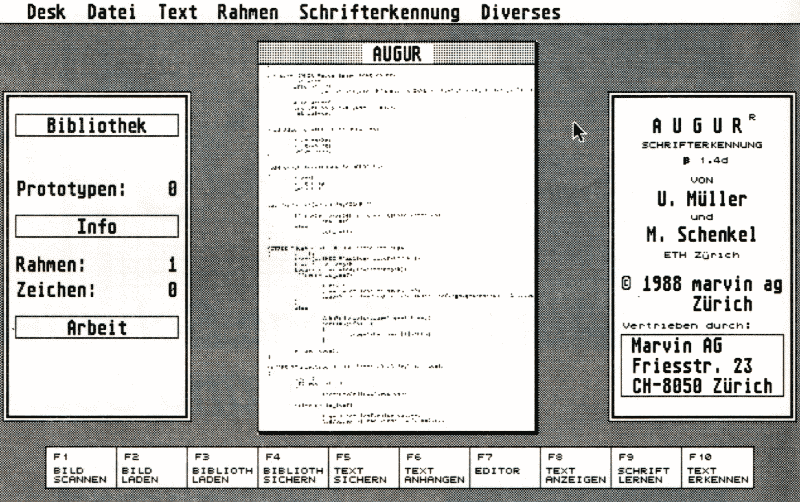
Ein unbekannter Schrifttyp erfordert eine Lernphase, in der Augur ein Zeichen anzeigt und der Benutzer die Bedeutung des angezeigten Zeichens eingibt. Diese Benutzereingaben werden in einer Bibliothek gespeichert, die man auf Diskette abspeichem kann, um sie wiederzuverwenden, wenn man zu einem späteren Zeitpunkt ein weiteres Dokument mit dem entsprechenden Schrifttyp lesen will.
Scanner
Bevor ein Text gelesen werden kann, muß er mit einem Scanner als Bildvorlage in den Computer geladen werden. Augur kann direkt mit zwei Modellen der Hawk-Scanner, dem sehr günstigen 200 dpi-Scanner CP 14 und der 400 dpi-Ausführung Hawk 432,0 arbeiten. Über ein spezielles Accessory mit zugehörigen Treiberprogrammen ist der Zugriff auch auf diverse Modelle der Firmen Panasonic, Chinon, Mikrotec oder Canon möglich. Auch soll es mit Hilfe des genannten Accessories bald möglich sein, Bilder im .IMG-Format von Diskette zu lesen.
Vorbereitung des Bildes
Um eine gute Texterkennung zu ermöglichen, ist es zuerst einmal sinnvoll, senkrechte und waagerechte Linien wie Unterstreichungen oder auch Zierrahmen aus dem gescannten Bild zu entfernen, da sie die Texterkennung massiv stören können. Dafür bietet Augur eine automatische Funktion.
Falls eine Seite nicht nur in einfachem Fließtext gesetzt ist, sondern auch Grafiken oder Abschnitte in anderen Schriftgrößen oder -arten enthält (z.B eine typische mehrspaltig gesetzte Zeitungsseite), müssen die einzelnen Blöcke markiert werden. Mit Grafiken kann Augur nichts anfangen, wenn ein Text also ein Bild enthält, muß er in Blöcke um das Bild herum zerteilt werden. Auch große Überschriften und Textspalten sollten jeweils einen eigenen Block erhalten, damit der Text in einer sinnvollen Reihenfolge gelesen wird.
Die Blöcke werden auf einer Übersichtsdarstellung der gescannten Seite einfach mit der Maus wie in einem Malprogramm markiert. Feine Korrekturen kann man dann in einer Vergrößerung vornehmen.
Texterkennung und ‘Lernen’ eines Schrifttyps

In dem ‘geblockten' Text kann die Texterkennung ausgelöst werden. Augur bearbeitet die markierten Blöcke der Reihe nach in zwei Schritten. Zuerst wird der Text in Zeilen zerlegt. Danach wird zeilenweise versucht, die Buchstaben zu erkennen. Es gibt drei Modi, die sich durch unterschiedliche Geschwindigkeit und Präzision auszeichnen. Dabei ist es keineswegs so, daß das Ergebnis des langsamsten und genauesten Modus' immer am besten ist. Wenn in diesem Prozeß ein Symbol im Text gefunden wird, dem Augur keinen Buchstaben zuordnen kann, fragt das Programm beim Benutzer nach. So vom Benutzer markierte Symbole werden in einer Bibliothek gespeichert. Augur 'lernt' also einen Schrifttyp beim ersten Erkennungsversuch. Je größer die Bibliothek wird, desto länger benötigt auch der Erkennungsvorgang: für unbekannte Symbole muß ja jetzt eine größere Bibliothek durchsucht werden. Außerdem steigt von einer bestimmten Bibliotheksgröße an auch die Fehlerwahrscheinlichkeit - schließlich könnten sich verschiedene Symbole ja ähnlich sehen, z.B. schlecht gedruckte 'i's und 'l's und ganz besonders Sonderzeichen wie Komma und Punkt oder Semikolon und Doppelpunkt.
Je nach Komplexität des Textes und der Anzahl der notwendigen Benutzerinteraktionen brauchte Augur bei unseren Versuchen für die Erkennung einer Seite zwischen 1 und 4 Minuten.
Sehr gelungen ist, daß die eigentliche Buchstabenerkennung im Hintergrund abläuft, also den Text auch dann weiterbearbeitet, wenn gerade ein unbekanntes Symbol ‘gelernt' wird. Die neu zu lernenden Zeichen werden dann nachträglich in den Text eingefügt. Auf diese Weise wird die Texterkennung durch die Benutzerinteraktion nicht nennenswert verlangsamt.
Probleme

Die Sicherheit der Buchstabenerkennung hängt, selbst bei optimalen Vorlagen, stark von der Scan-Helligkeit ab. Eine Vorlage muß optimal gescannt werden, damit die Buchstaben nicht ineinander überlaufen (zu dunkel) oder die einzelnen Buchstaben zerfallen (zu hell). Wenn Buchstaben nicht sauber getrennt werden können, versucht das Programm, Buchstabengruppen in die Bibliothek aufzunehmen, was zwar problemlos möglich ist, aber die Erkennungszeiten doch sehr verschlechtert und auch häufige manuelle Eingaben erfordert.
Schlimmer noch sind zerfallende Buchstaben: in diesem Fall interpretiert Augur Teile eines Buchstabens als Symbol und erwartet eine Zuordnung zu diesem Symbol. Im Gegensatz zu den oben erwähnten Buchstabengruppen, die bei zu dunkel gescannten (oder schlechten) Vorlagen auftauchen, ist hier auch keine Abhilfe möglich, es entstehen immer Fehler im erzeugten Text.
Augur arbeitet sehr zuverlässig mit Vorlagen von guter Qualität und Schrifttypen in Größen um 12 Punkt. Der einzige Fehler, der bei derartigen Vorlagen noch regelmäßig auftritt, ist die Verwechslung von Komma und Punkt. Wenn der Schrifttyp einmal gelernt ist, können weitere Seiten der gleichen Art praktisch ohne menschliche Mithilfe weitgehend fehlerlos gescannt und gelesen werden.
Es macht dabei zum Beispiel keinen Unterschied, ob eine gute Vorlage in einem klaren Helvetica-Schrifttyp oder in Fraktur gesetzt ist.

Schwierigkeiten gibt es jedoch mit schlechten Vorlagen. Es ist bei ungleichmäßig schwarzen Vorlagen kaum möglich, die Scanhelligkeit so einzustellen, daß wenigstens die größten Teile eines Dokumentes in geeigneter Form digitalisiert werden. Auch sehr kleine Schriften und unscharfe Konturen führen zu einer stark ansteigenden Fehlerhäufigkeit.
Zusammengefaßt läßt sich sagen: Die Schriftqualität der Vorlage, also Schwärzung. Randschärfe und Gleichmäßigkeit der Buchstabenform, ist entscheidend für die Erkennung mit Augur. Gegen ‘dreckige' Vorlagen oder leicht schräg stehende Schriften sowie mäßig kursive Schriften ist Augur erstaunlich tolerant.
Natürlich kann man mit einem flexiblen 200/300/400 dpi-Scanner erheblich mehr Vorlagen bearbeiten als mit einem einfachen Scanner, der nur eine Auflösung besitzt. Hauptproblem ist aber, daß man, wenn für eine Vorlage viel Probieren nötig ist, dadurch soviel Zeit verliert, daß sich die Frage stellt, ob Abtippen nicht doch schneller ginge. Auch steigt die Fehlerhäufigkeit, also die Anzahl der Verwechslungen, bei denen Augur einem Symbol einen falschen Buchstaben zuordnet, bei schlechten Vorlagen stark an. Solche Fehler sind sehr schwer zu korrigieren, da Augur in diesen Fällen nicht beim Benutzer rückfragt.
Ist ein Text einmal erkannt, kann er angezeigt und gespeichert werden. Dabei ist sowohl ASCII- wie 1st Word-Format vorgesehen. Auch der Aufruf eines Editors aus Augur heraus ist möglich.
Augur ist sehr komfortabel. Das Handbuch erlaubt auch Computerlaien, sich problemlos zurechtzufinden. Eine eingebaute Hilfefunktion gibt auch ohne Blättern im Handbuch Auskunft.
Augur - für wen?
Augur verspricht sehr gute Ergebnisse, wenn Vorlagen in guter Qualität vorliegen und nicht ständig Vorlagen von sehr unterschiedlichem Layout und stark wechselnder Qualität bearbeitet werden müssen. Für Geisteswissenschaftler beispielsweise, die alte Manuskripte ohne Abtippen archivieren wollen, ist Augur sicherlich keine übertrieben große Hilfe, da man sehr viel probieren und dennoch eine große Fehlerzahl im erkannten Text erwarten muß.
Natürlich hängt die Schwelle, ab der der Einsatz einer Texterkennung nicht mehr sinnvoll ist, stark von der eigenen Tippgeschwindigkeit ab. Außerdem macht es zumindest mir mehr Spaß, Augur beim Lesen zu helfen, als selbst zu tippen. Lediglich die Beseitigung der Fehlerkennungen im fertigen Text ist unerfreulich. Schließlich ist jedoch auch der Anschaffungspreis für Scanner und Software ein nicht ganz unwichtiges Argument. Ein hochwertiger Scanner sollte es schon sein, der billige Hawk CP 14 ist mit schlechten Vorlagen doch meist überfordert. Auch ist Augur mit knapp 2990,- DM nicht gerade ein Low-Cost-Produkt. Verglichen mit dem Preis-/Leistungsverhältnis von Texterkennungen auf anderen PCs schneidet Augur aber sehr gut ab.
CS
Bezugsadresse:
H. Richter
Hagenerstr. 65
5820 Gevelsberg