
Der ST im Uni-Einsatz

An Universitäten macht sich der ST als preiswerter Rechner mit ausreichender Rechenstärke und guter Grafik beliebt. Wir haben uns das Projekt TECHIS der Technischen Universität Berlin angeschaut: Erkennung chinesischer Schriftzeichen mit dem Atari.
Die Abkürzung TECHIS steht für “Teilautomatische Erkennung von chinesischer Schrift” und ist der Name eines interdisziplinären Projekts der Fachbereiche Linguistik, Kommunikationswissenschaften und Regelungstechnik. Projektziel ist die Erstellung eines Systems, das chinesische Schriftzeichen aus einer mit Video aufgenommenen Vorlage erkennt und Aussprache- und Übersetzungshilfen gibt. TECHIS hat eine Laufzeit von zwei Jahren und begann im Oktober 1986. Eine Verlängerung der Finanzierung um weitere zwei Jahre wird angestrebt.
Chinesische Zeichencodierung
Die gebräuchlichste chinesische Schrift, das Songti, besteht aus über 10 000 verschiedenen Wort- und Silbenzeichen. Die Zeichen sind im Vergleich zu unseren Buchstaben sehr komplex und unterscheiden sich teilweise nur minimal. Erschwerend für die Erkennung eines Textes kommt hinzu, daß Songti ohne Leerräume zwischen Wörtern geschrieben oder gedruckt wird.
Da natürlich auch in China Datenverarbeitung betrieben wird, gibt es eine Codenorm der Volksrepublik China, die mit dem hier üblichen ASCII-Satz vergleichbar ist. Dabei hat man es allerdings mit völlig anderen Dimensionen zu tun. Die Norm GB 2312-80 enthält 6763 verschiedene Zeichen, also das 26-fache des ASCII-Satzes. Sie werden unterteilt in 3755 häufige und 3008 seltenere Zeichen.
Das TECHIS-System arbeitet momentan mit den 3755 häufigeren Zeichen und erreicht dabei eine Trefferquote von 99,5 Prozent. Die ersten Entwicklungen und Versuche mit dem System fanden auf einer DEC microVAX II statt. Zu Demonstrationszwecken wurde ein MEGA ST 4 angeschafft und die Software portiert.
Videoscanning und Digitalisierung
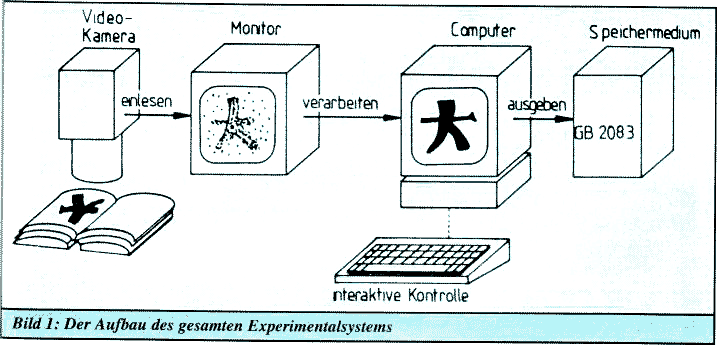
Bei beiden Systemen steht am Anfang eine CCD-Videokamera Siemens, die eine gedruckte Vorlage aufnimmt. Ein Buch, eine Zeitschrift oder sehr saubere Handschrift wird unter die Kamera gelegt, die dann das Videobild an einen Digitizer schickt. Den gesamten Aufbau des Experimentalsystems sehen Sie in Bild 1.
Für das Atari-System wird ein Digitizer von Print-Technik verwendet. Der PRO 8805 liefert eine Auflösung von 512 mal 256 Pixeln und arbeitet zufriedenstellend. Für eine hohe Auflösung, sprich sehr kleine Zeichen ist er allerdings nicht geeignet. Ideal wäre ein Flachbettscanner mit einer Auflösung von 800 Punkten pro Zoll. Momentan muß die Videokamera von Hand auf die Helligkeit und Größe der Vorlage eingestellt werden.
Mit der Digitalisierung steht im Rechnerspeicher eine in Pixel aufgelöste Aufnahme der Vorlage, auf die nun die Software angesetzt wird.
Die Bildverarbeitung
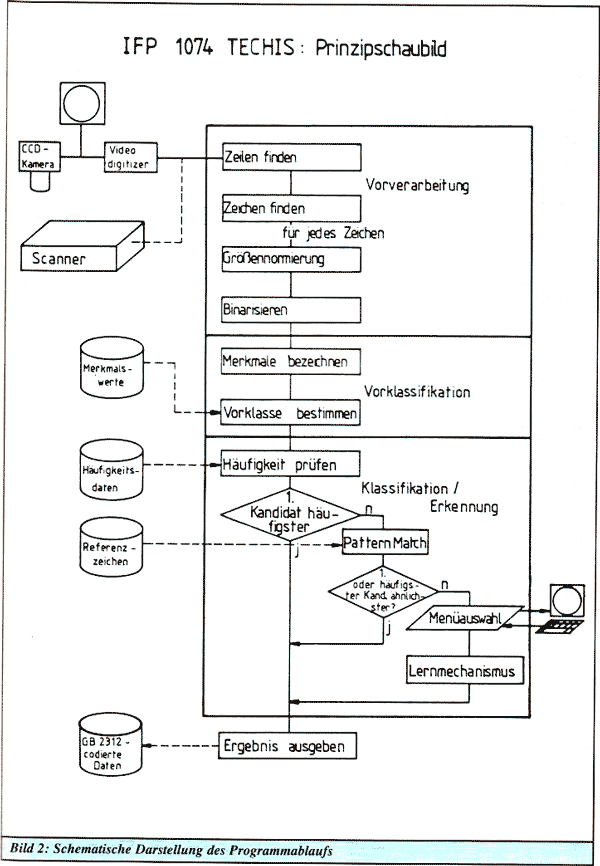
Der erste Schritt der Bildverarbeitung ist die Einteilung der Aufnahme in Zeilen und Zeichen. Danach können einzelne Zeichen analysiert werden.
Der Ausschnitt aus der Originalvorlage wird zunächst so normalisiert, daß er eine Größe von 64 mal 64 Pixel hat. Ein Glättungsalgorithmus kann zusätzlich Ausfransungen beseitigen, die beim Scannen oder Normalisieren entstehen. Nun ist das Zeichen soweit bearbeitet, daß ein Vergleich mit den bekannten Zeichen beginnen kann.
Das dabei verwendete Verfahren ist die Schwarzsprung-Verteilung in einer etwas verfeinerten Form. Ein Schwarzsprung ist der Übergang von einem weißen zu einem schwarzen Pixel im angepaßten Teilbild.
Bei der Verarbeitung wird zunächst in allen vier Richtungen horizontal, vertikal und in den Diagonalen jeweils die Anzahl der Schwarzsprünge und der schwarzen Pixel gezählt.
Nun werden die Pixel für die vier Richtungen aneinandergehängt. In der Horizontalen z.B. ergibt sich so eine Pixelkette von 64 mal 64, also 4096 Punkten. Dieser Vektor wird so in acht Teilvektoren zerteilt, daß sich in jedem eine gleiche Anzahl schwarzer Pixel befindet.
Das Zeichenbild ist jetzt in 32 Teilvektoren (jeweils acht für die vier Richtungen) zerlegt. Daraus errechnet das Programm 32 Merkmalswerte, die sich aus der Division der Schwarzsprünge in einem Teilvektor durch die Anzahl der Schwarzsprünge im ganzen Zeichenbild ergeben.
Durch die Berücksichtigung der diagonalen Richtungen wird dieses Verfahren sehr sicher. Verschobene oder fehlerhaft gescannte Zeichen erzeugen die gleichen Merkmalswerte, womit die Erkennung auf dieser Ebene sehr robust ist.
In einer Bibliothek stehen für die 3755 Referenzzeichen diese Merkmale zur Verfügung. Das Programm berechnet die Differenzen zwischen den Merkmalen des eingelesenen Zeichens und denen der Bibliothek. Dabei wird eine Gruppe von Zeichen mit möglichst kleiner Abweichung in einer Vorklasse zusammengefaßt, in der wahrscheinlich das korrekte Ergebnis zu finden ist.
Zur endgültigen Entscheidung werden zwei weitere Kriterien herangezogen. Zunächst kann die Häufigkeit der Kandidaten aus der Vorklasse in der Sprache Songti berücksichtigt werden. Wie schon genannt, gibt es in der riesigen Fülle der Zeichen einige die häufiger, einige, die seltener Vorkommen. Das System nimmt aufgrund dieser Werte an, daß ein Zeichen, das häufig in der Sprache ist, auch mit höherer Wahrscheinlichkeit der Vorlage entspricht.
Als zweites Kriterium wird mit einem Pattern-Match das gescannte Ausgangsbild mit den gespeicherten Referenz-Mustern der Kandidaten der Vorklasse verglichen. Dadurch ergibt sich ein Zeichen, das der Vorlage pixelweise am ähnlichsten ist.
War das Zeichen mit der geringsten Differenz bei den Merkmalen auch das häufigste, so kann der Code als Ergebnis ausgegeben werden. Falls dies nicht zutraf, nimmt das System den pixelweisen Vergleich vor. Als Treffer gilt nun das Zeichen, daß pixelweise am ähnlichsten und zugleich erster Kandidat der Vorklasse oder häufigstes Zeichen war.
Läßt sich an dieser Stelle immer noch kein Zeichen als Ergebnis ausgeben, muß der Benutzer in einer Menüauswahl das Ergebnis festlegen. An dieser Stelle kann ein Lernmechanismus in Gang gesetzt werden, bei dem die Referenzbibliothek erweitert wird.
Schon ein einmaliger Lernvorgang kann beim nächsten Auftreten des selben Zeichens eine automatische Erkennung bewirken. Je mehr Lernvorgänge vorgenommen werden, umso höher ist die Erkennungsrate des Systems. Seine Stärken werden also nicht nur vom eigentlichen Programm, sondern auch von Umfang und Qualität der verwendeten Referenzbibliothek ausgemacht. Den schematischen Programmablauf sehen Sie in Bild 2 abgebildet.
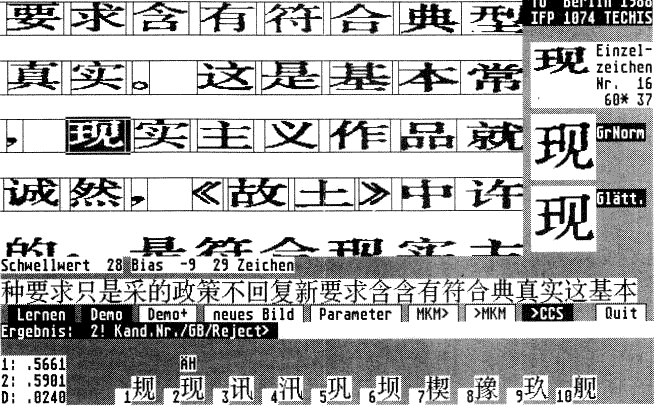
Eine Hardcopy während eines Programmlaufs auf dem Atari sehen Sie in Bild 3. Den größten Teil nimmt eine Darstellung des gescannten und digitalisierten Videobildes ein. Die Linien zeigen die Einteilung in Zeilen und Zeichen. Mit der Maus wurde ein Zeichen zur Analyse ausgewählt, das invertiert dargestellt ist.
Am rechten Bildschirmrand ist oben das gewählte Zeichen und die Bearbeitung durch Größennormierung und Glättung zu sehen. Die Zeichenbilder am unteren Bildschirmrand stammen aus der Referenzbibliothek und stellen die Vorklasse dar. Die zehn Zeichen wurden durch das Schwarzsprung-Verfahren über die Merkmalswerte ausgewählt und geordnet.
Die Tests auf Ähnlichkeit und Häufigkeit ergaben, daß der zweite Kandidat wahrscheinlich der Vorgabe entspricht. Er wird dem Benutzer als Ergebnis präsentiert, der hier noch das Zeichen zurückweisen kann. Beachten Sie den nur minimalen Unterschied zwischen erstem und zweiten Kandidaten.
Die Weiterverarbeitung
Steht der Code eines Zeichens fest, können aus einer Bibliothek Aussprache- und Übersetzungshinweise gelesen und auf dem Bildschirm angezeigt werden. Denkbar ist ab diesem Moment alles, was man auch mit ASCII-Zeichen machen kann. Möglich wäre z.B. die Übernahme des Textes in eine Textverarbeitung für chinesische Schrift. Für das Projekt beabsichtigt sind auch statistische Untersuchungen in chinesischen Texten und Experimente zur automatischen Übersetzung.
Bild 4 zeigt das Ergebnis der Weiterverarbeitung: Das Zeichen hat den Code 4754 und bedeutet “erscheinen” oder “Gegenwart”. “xian4” ist eine Aussprachehilfe. Daß es bisher nur zweimal vorkam und dennoch automatisch erkannt wurde, spricht für das angewandte Verfahren.
Das Programm
Wie schon angedeutet, ist der Atari ST hauptsächlich für Demonstrationszwecke angeschafft worden. Die Zeichenerkennung braucht erheblich länger als auf einer MicroVAX. Auch kommt das System mit einem Speicherbedarf von über 2 MegaByte schon an die Grenzen eines MEGA ST 4.
Das Programm wurde auf der MicroVAX in Fortran entwickelt, wobei die große Anzahl von Bibliotheken entscheidend war. Für die Portierung auf den ST fand der AC-Fortran-Compiler von Labsoft Verwendung. Um die Verarbeitungsgeschwindigkeit auf dem ST zu erhöhen, ist eine Programm-Version in C geplant. TECHIS zeigt, daß der Atari ST auch an Universitäten eingesetzt werden kann. Wenn seine Leistung auch nicht für sehr rechenintensive Arbeiten ausreicht, so kann er durchaus für Demonstrationszwecke eingesetzt werden. Sein größter Vorteil scheint hierbei - neben der leichten Mausbedienung und den Grafikfähigkeiten - der Preis zu sein. Dafür stehen ausreichende Leistungen und ein entsprechendes Angebot an Programmiersprachen zur Verfügung. Mit Festplatten und Laserdruckern erfüllt er inzwischen die Anforderungen an einen Mikro-Rechner im Uni-Einsatz.
Robert Tolksdorf