
Vom Papier zur Datenbank: 1. Teil Datennormalisierung
Die Informationsverwaltung ist die klassischste aller Computeranwendungen. Eine Datenbank, sei es nun eine für Großrechner, in Form eines Telefonbuches oder eine für Personal-Computer, ist nichts anderes als eine sinnvoll organisierte Informationssammlung.
Für die Computer der ATARI ST-Serie sind mittlerweile eine Vielzahl von Datenbanken auf dem Markt. Sie sind alle hervorragend zum Verarbeiten von Massendaten geeignet, wie z.B. im kaufmännischen Bereich (Lagerverwaltung, Personaldaten, Buchführungen), wo bekanntlich Unmengen von verschiedenartigen Informationen anfallen.
Eine Grundregel: Müssen mehr als 50 Daten ständig im Zugriff sein, lohnt es sich, über den Einsatz eines Datenbanksystems nachzudenken. Der Hauptvorteil liegt im schnellen Zugriff auf einzelne Datensätze und im freien Sortieren nach bestimmten Feldern innerhalb eines Datensatzes. Mein Kurs befaßt sich ausschließlich mit den relationalen Datenbanken, da ihre Bedeutung bereits heute beachtlich ist und in Zukunft noch steigen wird (Beispiel: PROLOG).
Um den Laien, wie aber auch allen anderen Interessierten, die Vorgehensweise beim Design einer Datenbank zu zeigen, ist dieser erste Teil des Kurses verfaßt. In weiteren geplanten Folgen werde ich ausgiebig auf die Datenmanipulationssprache sowie die Programmiersprache zum Erstellen lauffähiger Programme entgehen.
Ich werde heute den allgemeinen und prinzipiellen Aufbau relationaler Systeme erklären, die drei wichtigsten Regeln des Datenbankdesigns nennen und an anschaulichen Beispielen verdeutlichen.
Die folgenden Teile des Programmier-Kurses befassen sich dann mit speziellen Systemen, die auf dem ATARI verfügbar sind. Ich gehe besonders auf dB MAN Version 3.0 und STandard Base ein, weil sie sich am besten zum Schreiben professioneller Anwendungen eignen.
Außerdem bieten beide Programme eine Programmiersprache, die über die reine Datenmanipulation hinausgeht. Mit den zusätzlich implementierten Sprachelementen lassen sich leistungsfähige Anwendungssysteme schreiben, z.b. Buchführungen, Adreßverwaltungen oder Schallplattenarchive, die sehr einfach zu erstellen und zu erweitern sind und dennoch ein Höchstmaß an Benutzerfreundlichkeit aufweisen, obwohl die GEM-Oberfläche nicht genutzt wird. Die Programmiersprache “erzwingt” regelrecht, strukturierte Programme zu schreiben (keine Sprunganweisungen, ein Befehl pro Zeile usw.).
Die mächtigen Befehle ermöglichen eine schnelle Programmierung von Plausibilitätskontrollen (um Falscheingaben zu unterbinden), so daß spezielle Tools (z.B. Resource Construction Set) nicht benötigt werden. Ich meine auch, bei der Verarbeitung und Erfassung von Massendaten stört das GEM. Das ständige Wechseln von der Maus zur Tastatur verhindert einen “flüssigen” Arbeitsablaut.
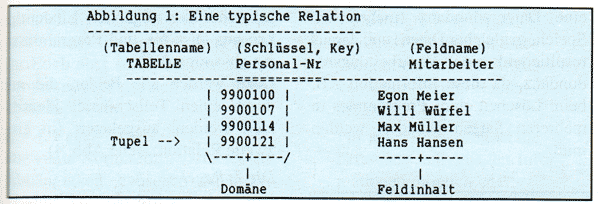
Der grundsätzliche Aufbau relationaler Systeme
In einer Relation werden die Daten in Tabellenform gespeichert. Die Zeilen der Tabelle sind die Datensätze, die (mit Namen versehenen) Spalten der Tabelle sind die Felder. Es ergibt sich eine “flache“ zweidimensionale Datei.
Zur einfachen und eindeutigen Identifikation eines Satzes (zum Wiederauffinden) dienen ein oder mehrere zusammengesetzte Felder, welche als Schlüssel (Key) deklariert werden, weil sie für jeden Satz einen bestimmten, sonst nicht vorkommenden Inhalt haben (Eindeutigkeit). Bei einem zusammengesetzten Key spricht man von einem Kombinationsschlüssel. Mehrere Tabellen sind also über gemeinsame Datenfelder miteinander verbunden. Diese Beziehungen werden auch Relationen genannt, daher auch die Titulierung “relational”. Die Gesamtheit aller Relationen bezeichnet man als Datenbank.
Die Charakteristik einer relationalen Datenbank:
Speicherorganisation für große Datenbestände mit einem System für deren effektive Wiederauffindung, bei der die Daten in sogenannten Relationen vorliegen. Auf die Tabellen können Mengenoperationen (Vereinigung, Durchschnitt, Differenz sowie Relationenoperationen, Entfernung von Spalten, Auswahl von Zeilen, Verbinden von Tabellen) angewandt werden, mit deren Hilfe Datenauswahl und Datenmanipulation möglich sind. Der Zugriff auf die Daten erfolgt über die Werte der gespeicherten Daten, so daß für den Benutzer keine sichtbaren Zeiger und Verkettungen existieren.
Jede Zeile mit gleichem Schlüssel wird als Tupel bezeichnet und ist in etwa mit einem Datensatz einer Datei vergleichbar (ein Tupel kann mehrere Sätze umfassen). Die Gesamtheit der verschiedenen Feldwerte eines Datenfeldes (das entspricht einer Spalte) heißt Domäne.
Das Schlüsselfeld sollte zur besseren Kenntlichkeit das erste Feld einer Tabelle sein (In meinen Beispielen ist der Key doppelt (======) unterstrichen).
DDL und DML
Für jedes Datenbanksystem gibt es eine spezielle Daten-Definitions-Sprache (Data Definition Language, DDL), mit deren Hilfe die Datenbank beim Anlegen in ihrem zukünftigen Aufbau beschrieben wird. Nachträgliche Änderungen (Hinzufügen von Feldern, Erweitern von Feldlängen usw.) sind problemlos möglich.
Mit der Data Manipulation Language was heißt das wohl in deutsch?), DML, werden die Daten eingegeben, abgerufen und gepflegt.
Die Sprache der relationalen Systeme unterscheidet sich aber erheblich von denen, die die Daten hierarchisch Mer nach dem Netzwerkmodell orientiert speichern.
Mit dem JOIN-Befehl (Vereinigung) kann aus zwei bestehenden Relationen eine neue, dritte Relation gebildet erden.
Unter Selektion versteht man das Ausblenden von bestimmten Zeilen einer Tabelle, mit Hilfe von Projektionen können Spalten aus der Sicht entfernt werden.
Mit diesen Befehlen verkleinert man die Datenbank auf die Spalten und Felder, die das jeweilige Anwendungsprogramm benötigt. Sie wird dadurch nicht physisch gelöscht; es erfolgt nur eine Eingrenzung der Betrachtung. Der vorherige Zustand ist jederzeit wiederherstellbar.
Diese Möglichkeiten zeigen den Vorteil relationaler Datenbanken: alle Operationen finden auf der Basis von Relationen statt. Das Ziel einer Operation ist dabei stets eine neue Relation, mit der weitergearbeitet werden kann.
Die Einfachheit der Datenmanipulationssprache ermöglicht endlich dem Endanwender den Zugang zu Datenbanken. Er braucht sich nicht wie ein Profi mit verschiedenen Satzarten, hierarchisch organisierten Zugriffspfaden und anderen schwer verständlichen Details zu befassen. Das Konzept einer Tabelle ist jedem zugänglich und hat im Grunde im mit elektronischer Datenverarbeitung nichts zu tun.
Der Anwender muß nur noch angeben, welche Daten er wünscht. Die Angabe, wie und wo die Daten zu finden sind, braucht er nicht zu machen. Dieses erledigt das Datenbanksystem, als Schnittstelle zwischen Mensch und Betriebssystem:
Anwendungsprogramm < - > Datenbanksystem < - > Betriebssystem < - > DB (DB=Datenbank)
In der Realität kann der richtige Entwurf von Relationen durchaus ein schwieriger Prozeß sein, da es gilt, die Daten sinnvoll (auch im Hinblick auf die Zukunft) anzuordnen.
Eine große Weitsichtigkeit wird vom Programmierer verlangt, damit nicht ein unsauberes Design später zu katastrophalen Konsequenzen führt.
Die folgenden Schritte erläutern den richtigen Aufbau.

Die drei wichtigen Regeln des Datenbankentwurfs
Ich werde die drei Regeln an einem Beispiel beschreiben, da sie im eigentlichen Wortlaut nicht verständlich genug sind.
Ich wähle ein Beispiel aus der Praxis: das Verwalten von Disketten und Programmen.
In Abb. 2 zeige ich eine völlig unstrukturierte Tabelle, die in keiner Form normalisiert ist. Die Nachteile dieser "Relation” sind schnell aufgezählt:
a) es können nur maximal drei Programme pro Diskette gespeichert werden
b) die Suche nach einem bestimmten Programm dauert zu lange, da alle Felder durchforstet werden müssen
c) sind weniger als drei Programme auf einer Disk gespeichert, bleiben Felder unbelegt (Platzverschwendung)
d) Löschen einzelner Programme kann Schwierigkeiten bereiten
Um die Fehler zu beheben, entfernen wir die Mehrfachfelder (Programm 1, Programm2, Programm3), deren Länge und Typ gleich sind, und schreiben sie untereinander weg. Damit führen wir die Relation in die 1. Normal form über (siehe Abbildung 3).
Die 1. Regel:
Alle Sätze eines Satztypes müssen dieselbe Anzahl von Feldern haben, d.h. Gruppen und multiple Felder sind verboten.
Demnach darf jedes Feld im Datensatz nur einmal und nicht mehrfach Vorkommen.
Die Vorteile sind schnell erkannt: es können beliebig viele Programme pro Disketten-Nummer erfaßt werden. Alle vorher aufgezählten Nachteile scheinen beseitigt.
Leider sind nach der Umgestaltung einige Einträge mehrfach vorhanden. Die Informationen über die Diskettenkapazität werden mit jedem Programm erfaßt, was eigentlich gar-nicht notwendig wäre. Es entsteht eine Datenredundanz (mehrfaches Speichern gleicher Daten) und daraus resultierend eine Verarbeitungsredundanz, da diese Information z.B. beim Löschen eines Programmes in mehreren Sätzen geändert werden muß.
Man erkennt, daß die Felder FREI und BELEGT zwar von der Disketten-Nummer, aber nicht vom Programm-Namen, d.h. nur von einem Teilschlüssel, abhängig sind (der Key setzt sich hier wegen der Eindeutigkeit aus Disk-Nr. und Programmname zusammen).
Dazu werden alle Felder, die nur durch einen Teilschlüssel identifiziert werden, ausgelagert (in eine zweite Relation, siehe Abb. 4)
Die 2. Regel:
In Relationen mit einem Kombinationsschlüssel muß jedes nicht dazugehörige Feld vom gesamten Kombinationsschlüssel abhängen. Felder, die nur von einem Teil des Keys abhängen, werden mit diesem Feld als Schlüssel separat gespeichert (Entkopplung).
Die Datenbank liegt dann in der zweiten Normalform vor, wenn sie beide Regeln erfüllt (was hier gegeben ist). Um noch die dritte Regel zu beschreiben, füge ich in die Tabelle PROGRAMM das Feld DISTRIBUTOR ein. Man erkennt schnell die entstehende Redundanz. Der Distributor wird mehrfach gespeichert. Damit auch die dritte Normalform erfüllt wird, entkoppeln wir nochmals in eine weitere Relation, DIST.
Zum Wiederauffinden vergeben wir eine interne Nummer. Sie wird als Fremdschlüssel bezeichnet, da sie nach außen hin nicht sichtbar wird.

Die 3. Regel:
Felder, die nicht Teil des Schlüssels sind, dürfen nicht untereinander abhängig sein. Ist das der Fall, werden auch diese voneinander abhängigen Felder in getrennten Relationen gespeichert.
Zum Erfüllen der dritten Normalform müssen alle drei Regeln eingehalten werden.
Der Vollständigkeit halber erwähne ich noch die vierte Regel (jawohl, die gibt’s auch). Ein Beispiel hierzu müßt Ihr Euch aber selbst ausdenken. Sie kommt in der Praxis eh selten (wenn überhaupt!) vor.

Die 4. Regel:
Die vierte Normalform verbietet jede Abhängigkeit zwischen Nicht-Primärschlüssel-Attributen. (???) Vielleicht existieren weitere Regeln, bitte schreibt mir, falls sie einer kennt oder selbst formuliert hat.
Damit wären wir mit der Datennormalisierung fertig. Die Vorteile der getrennten Relationen sind klar erkennbar; alle Nachteile sind beseitigt.
- Pro Diskette können beliebig viele Programme erfaßt werden; das Löschen eines Programms ist nach Angabe von Disk-Nr. und Namen möglich.
- Für jedes Programm ist die Erfassung individueller Informationen möglich (z.B. Bedienung, Monitor, Preis usw.).
- Die Adresse des zuständigen Distributors ist sofort verfügbar.
- Die Gesamtsumme aller Programme ist gleich der Anzahl der Tupel in der Tabelle PROGRAMM.
- Die Ermittlung des insgesamt freien oder belegten Disk-Platzes geschieht über die Summe der entsprechenden Domäne in der Tabelle DISK.
Wie geht’s weiter?
Bis zur nächsten Ausgabe werdet Ihr wohl die Schritte in der Entwicklung normalisierter Tabellen verstanden haben (mal ehrlich: so schwer ist es doch gar nicht!).
Ich werde im zweiten Teil meines Kurses endlich mit der praxisnahen Programmierung beginnen, und die Befehle zum Anlegen und Ändern einer Datenbank beschreiben. Bis dahin:
fröhliches Daten normalisieren !!

Paul Fischer