
Bilderspiele Teil 5
Mit den bisher dargestellten Mitteln können Sie einfache Strichzeichnungen auf den Bildschirm eines Computers bringen. So besonders hübsch ist das aber noch nicht. Etwas mehr gibt es doch zu tun. Werfen wir also einen Blick auf die Schritte, die hinführen zur künstlichen Wirklichkeit aus dem Computer…
Eine Strichzeichnung in bisheriger Form ist aus verschiedenen Gründen nicht besonders wirklichkeitsnah. Der erste und deutlichste Grund ist der, daß die ‘Wirklichkeit’ nicht aus lauter dünnen Strichen besteht, sondern aus Objekten, die meist ziemlich massiv (Spinnen weghören) und auch nur in den seltensten Fällen durchsichtig sind.
Nehmen wir an, dieses Problem sei gelöst. Wir haben massive Oberflächen. Jetzt stellt sich die Frage, warum natürliche Oberflächen aussehen, wie sie es eben nun mal tun. Die Antwort auf diese Frage heißt zuerst einmal ‘Beleuchtung’. Die Art des Lichtes, das auf ein Objekt fällt und von diesem reflektiert wird, ist entscheidend für sein Aussehen. Na gut, seien wir ehrlich, auch dies genügt nicht, man muß sagen: Die Art des Lichtes, das auf ein Objekt fällt, zu--ammen mit der Art, wie das Objekt Licht reflektiert, entscheidet über sein Aussehen.
Ein Objekt? Wo Licht ist, ist auch Schatten. Sobald es zwei Objekte gibt, besteht die Chance, daß man ien Schatten des einen Objektes auf dem anderen Objekt sieht. Sehr unangenehm und auch nicht leicht zu lösen, dieses Problem.
Nehmen wir einmal an, ein Objekt reflektiert nicht nur Licht sondern läßt auch noch Licht hindurch, sei also transparent. Hier spielen, mehr noch als bei der Reflektion, Materialeinflüsse eine große Rolle, schließlich werden Lichtstrahlen im allgemeinen beim Übergang vom einen in ein anderes Medium gebrochen. Daran, wie oft in den letzten Sätzen das Wort Licht gefallen ist, sehen Sie, wie wichtig dieser Punkt in Zukunft sein wird. Aber darüber machen wir uns später Gedanken. Zuerst einmal sollen uns die massiven Oberflächen interessieren.
Die Probleme mit guten Realismus-Effekten, die die herkömmlichen Verfahren bieten, werden uns dann zum Ende dieser Serie zu einem Verfahren führen, das mit großer Einfachheit und Eleganz, leider aber extremem Bedarf an Rechenzeit, fast alle Probleme herkömmlicher Verfahren zu beheben vermag, und das deshalb für professionelle Computergrafik heute unverzichtbar geworden ist. Es hört auf den bezeichnenden Namen Ray Tracing. Aber dazu an anderer Stelle mehr...
Wie kann man ein massives Objekt modellieren ? Dieses Problem ist uns nicht neu, wir haben darüber bereits nachgedacht und uns der Einfachheit halber dafür entschieden, es aus Flächenstücken, die aneinandergesetzt sind, aufzubauen. Ein Würfel zum Beispiel besteht dann aus... Na ? ...Richtig, 6 Flächen, 12 Linien und 8
Punkten. Wir müssen also nur unseren Objektdatentyp um eine Fläche erweitern, die aus einer Reihe von Linien zusammengesetzt ist. Das war nicht schwer. Nun stellt sich allerdings die Frage, wie man dem Computer klarmacht, welche Flächen eigentlich von einem beliebigen Blickpunkt aus sichtbar sind.
Dieses Problem beschäftigt die Programmierer von Grafiksystemen schon lange, und, um das gleich zu Beginn zu sagen, eine optimale Lösung gibt es nicht. Leider hat hier jeder bekannte Algorithmus einen Nachteil: entweder er ist langsam oder er ist schlecht, er braucht riesige Speichermengen (1000*1000 Pixel z.B. 7 MByte) oder ist nur für sehr spezielle Anwendungen brauchbar. Aus der ungeheuren Vielzahl der Möglichkeiten sollen in dieser Serie zwei Algorithmen, die in der Praxis besonders häufig zur Anwendung kommen, vorgestellt werden. Erwähnt sei zu der Vielzahl der Hidden-Surface-Algorithmen noch, daß auch das oben angesprochene Ray Tracing ursprünglich nur für diesen Zweck erdacht wurde. Welche Möglichkeiten in diesem Verfahren stecken, entdeckte man erst im Zuge der Beschäftigung mit Beleuchtungsmodellen usw. langsam Schritt für Schritt. Sie sehen, ich will Sie neugierig machen.
Diese Hidden-Surface-Routinen werden nicht mehr implementiert werden. Im Rahmen dieser Serie wäre eine vollständige Implementierung einfach zu umfangreich und in verständlicher Form auch zu wenig effizient. Ich möchte daher versuchen, Sie in die Lage zu versetzen, mit möglichst wenig Aufwand selbst entsprechende Routinen zu schreiben.
Zum Warmwerden ein etwas vereinfachtes Problem. Wir beschränken uns auf ein harmloses Objekt, z.B. den berühmten Würfel. Welche Teile sind von schräg oben sichtbar, welche nicht?
Stellen Sie sich einmal ein Viereck vor, dessen Ecken Sie streng im Uhrzeigersinn der Reihe nach numeriert haben. Jetzt drehen Sie das Viereck auf den Rücken. Fällt Ihnen etwas auf ? Jawohl, die Reihenfolge der Numerierung ändert sich. Wenn Sie ein im Uhrzeigersinn numeriertes Viereck umdrehen, ändert sich der Drehsinn der Numerierung. Diese kleine Nettigkeit werden wir verwenden, um dem Computer die Arbeit ein wenig zu erleichtern. Wie das ? Sie legen sich die sechs Flächen auf den Tisch, aus denen der Würfel besteht und numerieren ihre Ecken in der gleichen Reihenfolge durch, immer auf der gleichen Seite. Jetzt kleben Sie den Würfel so zusammen, daß die numerierte Seite immer außen ist. Wenn Sie den fertigen Würfel von einer Seite aus anschauen und Sie ihn aus transparentem Material gebaut haben, werden Sie sehen, daß die Rückseite jetzt einen anderen Drehsinn der Numerierung zeigt als die Vorderseite. Wenn Sie alle Seiten im Uhrzeigersinn numeriert haben, ist die Rückseite von Ihrem Blickpunkt aus jetzt entgegen dem Uhrzeigersinn numeriert. Bild 1 zur Illustration.

Wie bringt man das dem Computer bei ? Ganz einfach. Sie erinnern sich an das Skalarprodukt zweier Vektoren ? Betrag von Vektor 1 mal Betrag von Vektor 2 mal Cosinus des eingeschlossenen Winkels. Wunderbar. Sie kennen den Vektor, entlang dem Sie den Würfel betrachten (Vom Aug- zum Blickpunkt). Sie werden in Kürze einen Vektor kennen, der auf einer Fläche senkrecht steht, und dessen Richtung vom Drehsinn der Eckpunktnumerierung abhängt. Der senkrechte Vektor ist natürlich die Ebenennormale einer Seite, deren Richtung vom Drehsinn abhängt. Doch dazu später mehr, nehmen wir jetzt einfach mal an, wir kennten einen Vektor, der auf der Ebene senkrecht steht, und zwar so, daß er die Fläche immer auf der Seite verläßt, auf die Sie vorhin die Nummern geschrieben haben. Schauen Sie sich Bild 2 an. Das Vorzeichen des Skalarprodukts hängt nur vom Cosinus ab. Wenn der Cosinus positiv ist, ist es auch das Skalarprodukt. Und umgekehrt, wie Sie aus der letzen Folge wissen. Das Skalarprodukt ist, wie sich einfach aus dem Cosinus ergibt, immer dann positiv, wenn die beiden Vektoren in einem Winkel zwischen 270 und 90 Grad aufeinanderstehen. Bild 3 zeigt die Bedeutung dieser Aussage: Wenn der Sichtvektor und der Normalenvektor der Fläche wie oben definiert, aufeinanderzuzeigen, dann ist die Fläche eine Vorderseite und somit sichtbar (Vom vorgegebenen Blickpunkt aus). Andernfalls ist sie eben unsichtbar, weil sie eine Rückseite des Objektes ist, und Rückseiten kann man nicht sehen.

Das funktioniert so natürlich nur bei konvexen Körpern und dann, wenn Sie die Oberflächen alle im gleichen Drehsinn numerieren. Aber zurück zu der Oberflächennormalen. Sie erinnern sich an das Kreuzprodukt zweier Vektoren. Das Ergebnis ist ein Vektor, der auf beiden Vektoren senkrecht steht, also auf der von Ihnen aufgespannten Ebene. Bild 1 zeigt, daß sich die Richtung des Kreuzvektors aus dem Drehsinn ergibt, wenn man bei allen Polygonen der Fläche nach der Objekttransformation mit dem vom Sichtpunkt aus gleichen Punkt beginnend aus zwei Vektoren den Normalenvektor bildet. Man sucht sich also einen Punkt aus, zum Beispiel den am weitesten oben liegenden Punkt. Dann nimmt man den Vorgängerpunkt und errechnet aus beiden Punkten einen Seitenvektor. Das gleiche tut man mit dem folgenden Punkt. Bevor man daraus jetzt ein Kreuzprodukt bildet, sollte man feststellen, ob die Punkte auf einer Linie liegen, denn sonst ist das Kreuzprodukt gleich 0, was nicht sehr sinnvolle Folgen für das Skalarprodukt mit dem Sichtbarkeitsvektor hätte. Wenn alle Punkte der Fläche auf einer Linie liegen, sieht man sie genau von der Seite und kann die Fläche ignorieren, als sei sie unsichtbar. Wenn die Punkte nicht auf einer Linie liegen, wird also das Kreuzprodukt der zwei errechneten Vektoren gebildet und dann das Skalarprodukt mit dem Sichtvektor. Ist dieses kleiner 0, ist die Fläche sichtbar, andernfalls nicht. Dieser Test muß natürlich für jedes Polygon eines Objektes durchgeführt werden. Das ganze Ablaufdiagramm für diesen ‘Back-Lice-Removal’ genannten Vorgang finden Sie in Bild 4.

Falls Sie ein Grafiksystem vereinfachen wollen und dem Hidden-Surface-Algorithmus einige Arbeit sparen wollen, lohnt es sich, eine Backface-Removal-Routine vor die eigentlichen Hidden-Surface-Tests zu setzen. Die Anzahl der zu testenden Flächen wird nämlich radikal reduziert. Bei mehreren Objekten ist eine solche Routine alleine natürlich deshalb nicht ausreichend, weil sie nicht feststellen kann, ob eine dem Begehrter zugewandte Oberfläche von einer ebenfalls dem Betrachter zugewandten Oberfläche eines anderen Objekts verdeckt wird.
Das Verfahren setzt voraus, daß das Objekt bereits entsprechend dem Blickpunkt transformiert wurde, es muß allerdings vor der Projektion verwendet werden (Natürlich).

Hidden-Surface-Algorithmen
Es gibt grundsätzlich zwei Klassen on Hidden-Surface-Routinen: Solche, die die auszublendenden Oberflächen mit Hilfe einer Sortierung ermitteln und solche die es ohne Sortierung tun. Ich habe für beide Klassen einen viel verwendeten Algorithmus ausgesucht.
Zum Aufwärmen: z-Buffer
Der erste nennt sich ‘z-Buffer-Algorithmus’ und hat den Vorteil extrem einfach zu sein, vielleicht sogar der einfachste aller Hidden-Surface-Algorithmen. Gleichzeitig ist er schnell und kann leicht für Oberflächenschattierungen, also einfache Lichteffekte auf Oberflächen, erweitert werden. Hauptnachteil des Verfahrens ist der wahnsinnige Speicherbedarf. Im Zuge des Speicherpreisverfalls ist dieser Punkt allerdings nicht mehr so kritisch. Unangenehmer ist die Schwierigkeit, Transparenzeffekte und Bildqualitätsverbesserung mit Hilfe von Antialiasing (sorgt dafür, daß man die Computertreppchen in den Linien nicht so sieht) zu implementieren.
Der z-Buffer-Algorithmus ist unabhängig von der Komplexität der Szene, soweit es die Qualität und Fehlerhäufigkeit der Ergebnisse betrifft. Egal, wie wild Sie die Polygone im Raum verteilen - so einfach der z-Buffer zu programmieren ist, er verarbeitet alles, was viele seiner komplexeren Kollegen nicht von sich behaupten können. Wie bei allen derartigen Verfahren leidet natürlich die Effizienz - je mehr Polygone, desto länger dauert’s.
Das Verfahren arbeitet im Bildschirmkoordinatensystem, da ja Informationen, die auf die einzelnen Bildpunkte des Bildschirms bezogen sind, verarbeitet werden. Allerdings muß bei der Projektion die z-Koordinate jedes Punktes zwischengespeichert werden, da sonst ja keine Tiefeninformation mehr vorliegt, nach der man über Sichtbarkeit entscheiden könnte.
Wie funktioniert’s ?
Der Algorithmus bearbeitet jedes Polygon, also jede Fläche, einzeln; die Reihenfolge, in der die Flächen geliefert werden, spielt keine Rolle. Zu Beginn baut der Algorithmus einen großen Buffer auf, der in x- und y-Richtung die Größe des Bildschirms hat. In diesem Buffer wird jetzt für jedes bearbeitete Pixel eine Tiefeninformation gespeichert, wobei man im allgemeinen 20 Bit Tiefe für ausreichend hält. Bei einem Bildschirm mit 1000* 1000 Pixeln ist das aber schon ein Speicherbedarf von 6 Megabyte, allerdings kann man auf Kosten der Effizienz auch Speicher sparen, indem man immer nur ein Viertel oder die Hälfte des Bildschirms auf einmal bearbeitet (Na, wie groß muß ein z-Buffer für einen Bildschirm mit ATARI-Auflösung sein ???). Initialisiert wird dieser Buffer auf die größtmögliche Tiefe, nämlich unendlich, entsprechend dem Wert 0 oder auch SFFFFF, ganz nach Geschmack.
Für jedes Pixel, das innerhalb des Polygons liegt, wird jetzt aus den Koordinaten der Eckpunkte die z-Koordinate berechnet. Dafür gibt es verschiedene Möglichkeiten.
Dann wird der errechnete Wert mit dem im z-Buffer befindlichen Wert für die entsprechende Pixelposition verglichen. Liegt der errechnete Wert näher beim Betrachter, wird das Pixel auf den Bildschirm gemalt, mit der diesem Polygon zugeordneten Farbe. Außerdem wird der z-Buffer-Wert durch den neuen Wert ersetzt. Ist der z-Wert des Pixels weiter weg als der letzte z-Buffer-Wert passiert einfach gar nichts.
Ein einfaches Verfahren, nicht? Struktogrammsüchtige finden den Ablauf etwas formaler gestaltet in Bild 5. Etwas anschaulicher kann man das ganze vielleicht so erklären: Zuerst stellt man fest, welchen Teil (also welche Pixel) des Bildschirms ein Polygon bedeckt. Dann errechnet man für jedes dieser Pixel die Entfernung zum Betrachter (Die Lage des Polygons im Raum ist ja bekannt, die z-Koordinate der Eckpunkte wurde bei der Transformation zwischengespeichert). Wenn noch kein Punkt gefunden wurde, der an der entsprechenden Pixel-Position näher beim Betrachter liegt (was im z-Buffer notiert wäre), wird das Pixel auf dem Bildschirm mit den Polygonattributen (Farbe, Helligkeit o.ä) gezeichnet, andernfalls passiert überhaupt nichts. Damit bei der Bearbeitung des nächsten Polygons nichts schiefgeht, muß natürlich die Tiefe eines gezeichneten Punktes im z-Buffer notiert werden, damit sichergestellt ist, daß nur näher beim Betrachter liegende Punkte einen gezeichneten Punkt übermalen dürfen.
Der z-Buffer ist also nichts weiter als ein Notizblock, auf dem für jeden Bildschirmpunkt notiert wird, wie weit entfernt ein eventuell an dieser Stelle des Bildschirms gezeichnetes Objekt vom Betrachter entfernt ist. Nur wenn ein von dem Objekt besetztes Pixel näher ist, als die im z-Buffer gespeicherte Entfernung, ist es sichtbar, wenn es weiter entfernt ist, wird es einfach übermalt. Die Objekte müssen also vor dem Zeichnen nicht sortiert werden, es ist völlig egal, in welcher Reihenfolge Polygone bei einem z-Buffer bearbeitet werden. Für jedes Pixel merkt der Algorithmus sich, wie groß die aktuelle Mindestentfernung vom Betrachter ist, ab der ein Pixel gezeichnet wird, bzw. verdeckt ist. Deshalb muß am Anfang der z-Buffer auch auf einen festen Wert initialisiert werden, der die maximal mögliche Entfernung angibt. Punkte des ersten Polygons, das bearbeitet wird, liegen dann auf jeden Fall näher, als jeder bisherige Punkt.

Beim nächsten Polygon könnten schon Teile übergangen werden, die weiter entfernt liegen, als das erste bearbeitete Polygon.
Hier zeigt sich auch ein Vorteil, der sich aus dem 3D-Clipping ergibt. Die Tiefe des z-Buffers ist leichter sinnvoll auf einen bestimmten Wert zu begrenzen, wenn man die Tiefe ‘unendlich’ für den Ausschnitt der ‘Welt’, der gezeigt werden soll, ausschließen kann. Nach dem 3D-Clipping ist ja nur noch ein in der Tiefe beschränkter und bekannter Teil der ‘Welt’ übrig.
Hier kann man dann für die Tiefeninformation im z-Buffer auf Fließkommazahlen verzichten; eine Fließkommazahl, die üblicherweise mindestens 7 Stellen Genauigkeit aufweist, benötigt mindestens 4 Byte, was den z-Buffer doch etwas unhandlich groß macht. Wenn die x- und y-Genauigkeit im Bereich von 1000 Schritten (Bedenken Sie: Unsere ‘Welt’ befindet sich ja in dem Stadium der Darstellung, in dem der z-Buffer zur Anwendung kommt, bereits in der zu Bildschirmkoordinaten transformierten Form !) in jeder Richtung liegt, muß man ja nicht in z-Richtung 1038 Schritte, jeweils mit 6 Stellen Genauigkeit vorsehen. Üblicherweise geht man davon aus, daß bei der genannten Bildauflösung eine Tiefengenauigkeit von 1 bis 16 Millionen Schritten völlig ausreichend ist, entsprechend 20 - 24 Bit. Sichtbare Fehler durch falsch errechnete Tiefeninformation (Rundungsfehler müssen ja schließlich vermieden bzw, berücksichtigt werden) treten bei dieser Auflösung dann nicht mehr auf.
Als Zahlenformat wird meist Festkommadarstellung verwendet, da kaum ein System von Haus aus über ein Zahlenformat mit 20 oder 24 Bit Größe verfügt (meist nur 16 oder 32 Bit). Integer, oder in diesem Fall Long_Integer-Darstellung tut’s natürlich auch, beide Darstellungen haben gegenüber dem Fließkommaformat auch noch den nicht unbeträchtlichen Vorteil, daß sich damit erheblich schneller rechnen läßt. Schließlich muß noch das Problem betrachtet werden, wie man die Entfernung eines beliebigen in einem Polygon enthaltenen Punkts vom Betrachter errechnet. Eine einfache und komfortable Lösung sei hier kurz skizziert; weil sie aber so einfach ist, nicht im Detail ausgeführt:
Polygone liegen in einer Ebene. Ein Polygon besteht aus mindestens drei Punkten, was es möglich macht, eine eindeutige Ebenengleichung für es aufzustellen bzw. zu errechnen. Damit lassen sich aber die Koordinaten jedes einzelnen Punktes in der Ebene, also auch innerhalb des Polygons berechnen. Was will das Herz mehr?
Für Ästheten: Der Painters-Algorithm
Besonders elegant kann man den Ansatz des z-Buffer-Algorithmus eigentlich nicht nennen, denn jedes Pixel muß auf seine Tiefe geprüft werden, alle Pixel, die überhaupt Vorkommen, müssen mindestens einmal bearbeitet werden. Wenn nur zwei Polygone gezeichnet werden sollen, die dazu noch weit auseinanderhegen, müssen trotzdem alle Pixel, die in diesen Polygonen hegen, einzeln getestet werden, obwohl ganz offensichtlich ist, das diese Objekte sich nicht verdecken können - Kurz: der z-Buffer-Algorithmus ist zwar relativ effizient, aber irgendwo eine ‘Brüte Force’-Methode, also rohe Gewalt. Der Maleralgorithmus, wie die deutsche Übersetzung seines Namens lautet, arbeitet da ganz anders. Er nutzt, wenn auch nur in bescheidenem Maße im Vergleich zu wiederum komplexeren Algorithmen, die Eigenschaften der Szene, die zu zeichnen ist, aus. Der Name bezeichnet das Prinzip: Ein Maler malt auf die Leinwand zuerst die am weitesten hinten hegenden Teile der Szene und übermalt sie dann teilweise mit weiter vorne hegenden Bildteilen. Genauso tut es der Painters-Algorithm:
Stelle fest, wie weit hinten jedes Objekt hegt, sortiere und male die Objekte dann von hinten nach vorne. Das Problem ist klar: Wie stellt man fest, wie weit hinten ein Objekt hegt?
Schließlich hat ein Haus ja nicht nur eine Tiefe, sondern es beginnt z.B. irgendwo vome im Bild und hört im Hintergrund auf... Das ist gar nicht so einfach. Aber dazu später mehr.
Der Hauptunterschied zum z-Buffer-Verfahren hegt darin, daß die Teile des Bildes, die Objekte, bzw. die Polygone, aus denen die Objekte bestehen, nicht in Pixel zerlegt, sondern als Ganzes behandelt oder, nötigenfalls, in mehrere Polygone zerteilt werden. Immer wird eine Fläche aber als Ganzes behandelt, das Ergebnis des Algorithmus ist nicht ein aus Pixeln bestehendes Bild, sondern eine eindeutig nach z-Koordinaten sortierte Liste von Polygonen, die dann einfach nur noch in der sortierten Reihenfolge gezeichnet werden müssen; der Unterschied läßt sich auch an der Komplexität der verwendeten Zeichenbefehle ablesen: Für den z-Buffer-Algorithmus braucht man nur einen Befehl zum Setzen von Pixeln, da das Bild, egal wie kompliziert es ist, immer in Pixel zerlegt wird. Das Ergebnis des Maler-Verfahrens kann mit komplexen Befehlen wie ‘Zeichne gefülltes Polygon’ dargestellt werden. Der Painters-Algorithm profitiert also zum Beispiel von schnellen Grafikprozessoren. die automatisch und ohne Prozessoraktivität gefüllte Polygone zeichnen können, der z-Buffer-Algorithmus kann solche Hardware-Grafikerweiterungen nicht nutzen.
Im allgemeinen ist der Maler-Algorithmus rechenaufwendiger, was durch schnelle Grafikhardware zum Teil ausgeglichen werden kann. Dafür ist der Speicherbedarf gering, die Effizienz immer noch gut. Im Verhältnis zu anderen Verfahren ist auch die Komplexität des Algorithmus erträglich, die Erweiterbarkeit jedoch auch nicht besser (eher schlechter) als beim z-Buffer-Algorithmus. Schatten oder Transparenz sind bei beiden gleich schwer zu implementieren. Dennoch, auf Mikrocomputern ist dieses Verfahren mit Abstand das beliebteste, auch wenn sich das mit steigenden Speichergrößen in Zukunft sicherlich ändern dürfte. Vor allem kann man den Maler-Algorithmus auch in unvollständigen Varianten implementieren, die einfache Objekte schnell und korrekt malen, bestimmte schwierige Probleme aber nicht lösen können. In Bild 6 sehen Sie die typischen Schwierigkeiten für Hidden-Surface-Algorithmen: Sich durchstoßende oder gar zyklisch überlappende Objekte. So etwas mag eine einfache Implementierung des Painters-Algorithm gar nicht, genausowenig konkave Objekte. Man kann die Probleme zwar lösen, doch immer auf Kosten der Einfachheit und vor allem der Effizienz. Zur Erinnerung: Da der z-Buffer keinerlei Eigenschaften der Szene nutzt, sondern sie in Einzelpixel auflöst, gibt es derlei Probleme dort nicht. Einfache Entscheidungshilfe: Haben Sie genug Speicher für einen z-Buffer, dann nehmen Sie einen, wenn nicht, versuchen Sie’s mit einem Maler-Algorithmus, besonders, wenn Sie einen schnellen Grafikprozessor haben... CAD 3D zum Beispiel nutzt aus Effizienzgründen ebenfalls einen unvollständigen ‘Maler’, schließlich hat ja nicht jeder ST über 1 MByte Speicher.

Zuerst einmal soll der Ablauf einer vollständigen ‘guten’ Implementierung dargestellt werden, später werde ich noch verraten, welche Schritte Sie in einfachen, ‘fehlerhaften’ Varianten weglassen können.
Zuerst einmal werden alle Polygone, so wie sie sind, nach der kleinsten vorkommenden z-Koordinate sortiert. Dazu eignet sich zum Beispiel sehr gut ein Quicksort-Algorithmus. Wenn Sie Glück haben, können Sie die Polygone jetzt schon zeichnen (mit den am weitesten hinten liegenden beginnend natürlich) und alles stimmt. Leider wird das nur bei den allerprimitivsten Szenen, in denen es keinerlei Polygone gibt, die sich irgendwie überlappen, so funktionieren. Also weiter. Sie fangen hinten in der Liste an. Testen Sie das letzte Polygon in einem z-Minimax-Test gegen das nächste (d.h. korrekterweise gegen alle vor dem aktuellen Polygon liegenden Polygone). Halt, Stop. Z-Minimax-Test ? Ein Minimax-Test vergleicht die größten und kleinsten Koordinaten - zum Beispiel zweier Boxen - miteinander und stellt fest, ob sie sich überschneiden. In diesem speziellen Fall interessiert uns, ob sich die Boxen um die Polygone in der z-Koordinate überschneiden, ob also das letzte Polygon in der Liste auch wirklich ganz und vollständig hinter dem nächstfolgenden liegt. Da wir ja nur nach der kleinsten z-Koordinate sortiert haben, könnte es sein, daß die größte z-Koordinate des letzten Polygons größer als die kleinste z-Koordinate des vorletzten ist (Bild 7b). In diesem Fall wäre es möglich, daß das letzte Polygon das vorletzte und eventuell auch andere, die noch vor dem vorletzten in der Liste liegen, verdeckt. Um dies auszuschließen, müssen weitere Tests durchgeführt werden. Nur wenn sichergestellt ist, daß das letzte Polygon der Liste kein anderes verdecken kann, darf es gezeichnet und aus der Liste entfernt werden.
Das Prinzip noch einmal kurz zusammengefaßt, bevor wir uns den weiteren Tests zuwenden: Zuerst werden die Polygone nach einem einfachen Kriterium sortiert, das keinesfalls sicherstellt, daß sich die Polygone nicht mehr gegenseitig überlappen. Die entstehende Liste wird von hinten nach vorne abgearbeitet, ein Polygon nach dem anderen gezeichnet. Vor dem Zeichnen muß aber sichergestellt sein, daß das hinterste Polygon kein anderes überdeckt, da ja alle anderen wie auf einer Leinwand über die bereits gezeichneten gemalt werden und diese so ganz oder teilweise verdecken. Sinnvollerweise ordnet man die Tests so, daß zuerst die wenig rechenaufwendigen Versuche zur Bestätigung der richtigen Reihenfolge gemacht werden. Ist ein Beweis erfolgreich, kann das Polygon gezeichnet werden, und man kann sich den Rechenaufwand für die schwierigen Tests sparen. Der allereinfachste Test ist, wie bereits ausgeführt, der Minimax-Test, da hier nur verglichen werden muß, ob das Polygon vollständig hinter den anderen Polygonen liegt oder nur teilweise.

Wenn ein Polygon nur teilweise hinter den anderen liegt, sollte man als nächstes einen Minimaxtest in x- und y-Richtung durchführen. Wenn hierbei keine Überlappung zwischen dem aktuellen und einem weiter vorne liegenden Polygon festgestellt werden kann, kann das hintenliegende auch kein anderes verdecken. Wie auch ? Von vorne gesehen, ist es in diesem Fall ja vollständig sichtbar. Wenn Sie z.B ein Polygon in der rechten oberen Ecke haben und einen Haufen in der linken unteren, kann das Polygon rechts oben die Polygone links unten beim besten Willen nicht verdecken und kann somit gezeichnet werden. Der z-Buffer müßte ein solches Polygon trotzdem in Pixel auflösen (wie bereits oben erwähnt). Beachten Sie bitte, daß ein erfolgreicher Minimax-Test in zwei Dimensionen nicht bedeutet, daß sich die Polygone selbst schneiden müssen. Es werden ja nur zwei Boxen um die Polygone herum verglichen. Dadurch ist nur der negative Ausgang des Tests beweiskräftig: Wenn sich nicht einmal die Boxen um die Polygone schneiden, dann tun’s die Polygone selbst natürlich auch nicht. Vergessen Sie nicht, daß Sie auch diese Tests mit allen vor dem aktuellen Polygon liegenden Polygonen durchführen müssen.
Der nächste Test ist erheblich komplizierter. Hier müssen Sie nämlich feststellen, ob sich die Polygone schneiden, oder, etwas exakter formuliert, ob ein Polygon vollständig auf einer Seite der durch das andere Polygon gebildeten Ebene liegt oder nicht.. Wenn sich die Polygone nicht schneiden, ist bewiesen, daß das hintere Polygon das vordere nicht überdecken kann. Was bedeutet, daß Sie das hintere Polygon getrost zeichnen und vergessen können. Wie geht’s ? Am besten holen Sie tief Luft und die Zeitung mit der Folge über Clipping hervor. Das Problem ist nämlich nichts anderes als ein Clipping-Test der beiden Polygone unter leicht veränderten Bedingungen; es gibt nur eine Clippingebene, nämlich die Ebene des einen Polygons, allerdings muß die entscheidende Begrenzung des Clipping-Windows auf dieser Ebene nicht unbedingt rechteckig sein, sondern hängt von der Polygon-Form ab. Es ist aber wahrlich nicht schwer. Sie können, alternativ, aber auch einfach die beiden Polygonebenen gegeneinander schneiden und die Schnittgerade vergleichen; das ist auch nicht schwieriger. Wenn sich die Polygone nicht schneiden, haben Sie wieder einmal einen Beweis, daß Sie das aktuelle Polygon gefahrlos zeichnen können.
Der letzte Test ist am unangenehmsten: Wenn alles andere keinen Beweis liefert, daß sich nichts verdecken kann, muß man in den sauren Apfel beißen und die Projektionen der Polygone auf die Bildebene berechnen. Dort muß man dann feststellen, ob sich die Polygone irgendwo überlappen. Wohlgemerkt: Die Polygone, nicht die umgebenden Boxen. Das ist zwar absolut nicht schwierig, aber sehr, sehr mühsam (Projizieren können wir ja; bzw., wenn die Routine, was sinnvoll ist, erst in Bildschirmkoordinaten angewandt wird, haben wir ja schon längst projiziert). Aber was hilft’s?.. Wenn die Projektionen sich nicht schneiden, kann das aktuelle Polygon gezeichnet werden. Wenn keiner der Tests den nötigen Beweis liefert, wird sich Ihr Computer ärgern, denn dann müssen das letzte und das vorletzte Polygon vertauscht und alle Tests wiederholt werden. Falls das immer noch nicht zu einem durchschlagenden Erfolg führt, sitzen wir in der Tinte (königsblau). Dann handelt es sich bei unserem Problem nämlich um eine zyklische Überlappung von Polygonen. In diesem Fall bleibt uns nichts anderes übrig, als das hinterste Polygon in zwei Teile zu teilen, die Liste neu zu sortieren und von vorne zu beginnen. Das Teilen eines Polygons erledigt man am besten über die Schnittgerade zweier Ebenen - Sie müssen das aktuelle Polygon entlang der Ebene des vorletzten Polygons zerschneiden.
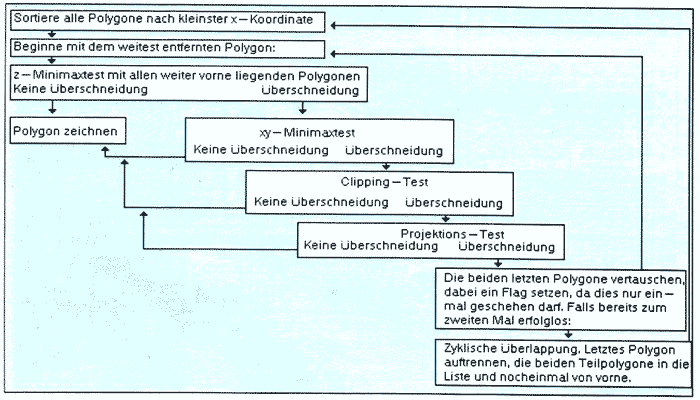
Sie sehen, wenn Sie einen wirklich korrekten ‘Maler’ basteln wollen, sind Sie ganz schön beschäftigt, einfach ist das nicht mehr. Sie können, wenn Sie Bildfehler bei komplexen Objekten in Kauf nehmen wollen, natürlich einfach die schwierigeren Tests ignorieren. Viele Programme machen das so, allerdings sieht man das auch oft. In Bild 8 sehen Sie den Algorithmus in einem Diagramm. Verdeckte Oberflächen sind wirklich ein trockenes Problem. Aber da hilft leider nichts, wenigstens grundsätzlich sollte man verstanden haben, wie sowas geht, jedenfalls dann, wenn in der nächsten Folge die Erleuchtung über Sie kommen soll. Dort werden wir uns nämlich mit dem Licht auseinandersetzen, das für all diesen Ärger verantwortlich ist (Wie beim Vogel Strauß - Was man nicht sieht, ist auch nicht da). Langsam aber sicher haben wir dann die Regionen erreicht, in denen es spannend wird -die Methoden, mit denen man realistische Computerbilder erzeugen kann.
CS
