
Einführung in FORTH Teil IV
Forth ist keine Sprache, die ihr Innerstes vor dem Anwender versteckt. Im Gegenteil. FORTH lädt gerade dazu ein, einen Blick unter die Oberfläche zu werfen. So läßt sich ohne großen Aufwand der vom Compiler erzeugte Kode inspizieren und modifizieren. Genauso einfach ist es, den FORTH Compiler zu steuern bzw. zu erweitern. In dieser Folge geht es zunächst um den allgemeinen Aufbau von Wortdefinitionen. Der einheitliche Aufbau der unterschiedlichsten Worttypen ist das Geheimnis des simplen, aber dennoch enorm leistungsfähigen Arbeitsprinzips von FORTH.
Aufbau von Wortdefinitionen
In FORTH dreht sich alles um Worte. Unter einem Wort wird allgemein ein Stück FORTH Kode verstanden, das mit einem Namen versehen in einem bestimmten Bereich des Arbeitsspeichers untergebracht ist. Dieser Bereich wird naheliegenderweise Wörterbuch genannt und ist das zentrale Element eines jeden FORTH Systems. (Zwar ist das Wörterbuch in der Regel in kleinere Untereinheiten, Vokabulare genannt, aufgeteilt, allerdings ist diese Tatsache für das weitere Verständnis dieses Abschnittes unbedeutend.) Das Wörterbuch wurde bereits bei der Entwicklung des FORTH Systems mit einer bestimmten Anzahl (je nach Art der Implementation und Fleiß der Entwickler) von Wörtern gefüllt. Dieses Kernwörterbuch enthält einerseits Wörter, die zum Betrieb des Systems unbedingt notwendig sind (wie z. B. QUIT, der Textinterpreter, der Eingabedaten auswertet) und andererseits Worte, die dem Benutzer die tägliche Entwicklungsarbeit erleichtern sollen (dazu gehören z. B. Worte, mit denen XBIOS-Aufrufe möglich sind). In den seltensten Fällen wird sich der Benutzer mit den Kern-Wörtern zufrieden geben, sondern das Wörterbuch um neue Wortdefinitionen erweitern.
Das Wörterbuch wird durch einen Zeiger, dem Wörterbuchzeiger (DP für engl. Dictionary Pointer) verwaltet. Der DP zeigt stets auf die nächste freie Speicherzelle im Wörterbuch, jene Speicherzelle, in der der nächste Eintrag erfolgen wird. Der Inhalt des DP kann durch das Wort ’HERE’ auf den Stack gebracht werden:
HERE U. 36108 ok
Dieser Wert bezieht sich auf VOLKS-FORTH 3.8 und ist selbstverständlich systemabhängig. Der Aufbau des Wortes ’HERE’ ist simpel und soll daher einmal kurz vorgestellt werden:
: HERE DP @ ;
Zunächst wird die Adresse der Benutzervariablen DP auf den Stack gebracht. Anschließend wird der unter dieser Adresse abgespeicherte 16 Bit Wert (der momentane Stand des Wörterbuchzeigers) in den Stack geholt. Die Ausgabe mit ’U.’ ist notwendig, da es sich bei der Adresse um eine Zahl größer als 32768 handelt, die in 16 Bit FORTH Systemen als vorzeichenbehaftete Zahl behandelt wird.
Der Inhalt des DP bestimmt die Adresse, ab der der nächste Eintrag in das Wörterbuch untergebracht wird.
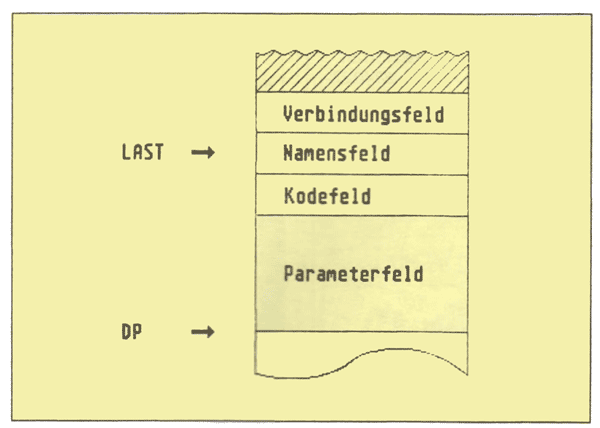
Der Benutzer kann DP z. B. mit Hilfe des Wortes ALLOT manipulieren, wobei ALLOT die oberste Zahl im Stack zum momentanen Wert von DP addiert. Auch jede Erweiterung des Wörterbuchs um eine neue Wortdefinition verändert den Inhalt von DP, da jede Wortdefinition eine bestimmte Anzahl von Bytes im Wörterbuch belegt. Jede Wortdefinition (auch Konstanten, Variablen usw. werden als Wortdefinitionen bezeichnet) weist einen einheitlichen Aufbau auf. Abb. 1 zeigt den allgemeinen Aufbau einer Wortdefinition, wie sie im Wörterbuch abgelegt wird.
Wie wird eine Wortdefinition erzeugt?
Eine Wortdefinition wird generell durch ein sog. Definitionswort erzeugt. Drei solche Definitionsworte haben wir bereits kennengelernt, nämlich ’CONSTANT’ und 'VARIABLE'. Allen drei Definitionsworten ist gemeinsam, daß Sie Wörter definieren, die zwar im Wörterbuch einen ähnlichen Aufbau aufweisen, beim Aufruf aber ein recht unterschiedliches Verhalten zeigen. Beginnen wir mit dem Definitionswort dem wichtigsten Definitionswort in FORTH. Mit wird eine Doppelpunktdefinition eingeleitet, wie z. B. im folgenden Beispiel:
: SUMME DUP + ; ok
Nach Eingabe von wird FORTH von Ausführungsmodus in den Compilemodus geschaltet. Alle nun folgenden Worte werden in das Wörterbuch eingetragen und nicht mehr direkt ausgeführt. Erst beendet den Compilemodus und das System kehrt in den Ausführungsmodus zurück.
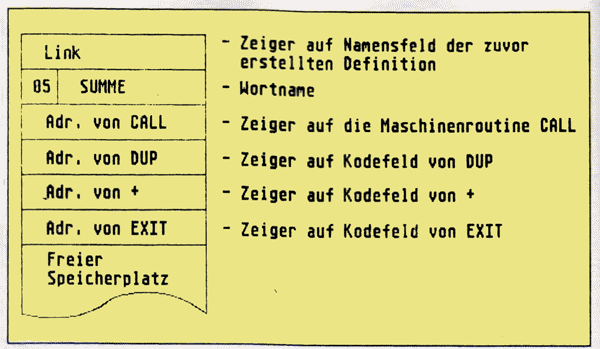
Aus der Differenz des Nachher-/Vorher-Zustandes des Wörterbuchzeigers DP erhalten wir einen Aufschluß über die Anzahl der Bytes, die unsere neue Definition im Speicher belegt. In diesem Fall sind es genau 16 Bytes. Dieser Wert ergibt sich aus der Differenz zweier Adressen, nämlich dem Ende (diese Adresse läßt sich durch HERE bestimmen) und dem Anfang der Wortdefinition (diese Adresse, genauer gesagt handelt es sich um die Namensfeldadresse von SUMME, liefert die Benutzervariable LAST, die im allgemeinen die Namensfeldadresse der zuletzt gemachten Wortdefinition enthält).
Was wurde in den 16 Bytes gespeichert? Abb. 2 zeigt den Aufbau der Doppelpunktdefinition SUMME im Speicher. Durch Eingabe von
LAST @ 2- 16 DUMP
können Sie sich den Speicherbereich, den die Wortdefinition SUMME belegt ausgeben lassen und so selber deren Aufbau untersuchen. Etwas komfortabler geht es mit einem Decompiler, welcher ebenfalls in VOLKSFORTH 3.8 enthalten ist. Seine Aufgabe besteht darin, den Quelltext von Wortdefinitionen wieder zu „rekonstruieren“ und auszugeben.
Schauen wir uns den Aufbau der einzelnen Felder etwas genauer an. Da wäre zunächst das Verbindungsfeld. Es enthält einen 16 Bit Zeiger, der auf das Namensfeld der zuletzt gemachten Definition zeigt. Auch diese Definition enthält in ihrem Verbindungsfeld wiederum einen Zeiger auf die davor gemachte Definition. Da durch dieses Feld so alle Wörter des Wörterbuches miteinander verbunden werden, wird es als „Link-“ bzw. Verbindungsfeld (engl. Link = verbinden) bezeichnet. Dem Verbindungsfeld folgt das Namensfeld, das mit einem Byte beginnt, das u. a. die Länge des Wortnamens enthält. An dieses Byte schließt sich der Wortname des betreffenden Wortes an. Dem Namensfeld folgt das Codefeld, welches ebenfalls einen 16 Bit Zeiger enthält. Dieser Zeiger adressiert eine Maschinenroutine mit, die für das Ausführungsverhalten des betreffenden Wortes verantwortlich ist. Sie wissen, daß ein durch definiertes Wort bei seiner Ausführung alle in ihm enthaltenen Komponentenwörter zur Ausführung bringt. Genau dieses Verhalten wird durch die Maschinenroutine festgelegt, auf die der Codefeldzeiger eines durch definierten Wortes zeigt (diese Routine wird meistens als CALL bezeichnet). Somit enthalten alle durch definierten Worte den selben Zeiger im Codefeld.
Über den sog. Adreßinterpreter wird die durch das Codefeld adressierte Maschinenroutine angesprungen und das betreffende Wort zur Ausführung gebracht. Auch hier zeigt sich wieder sehr eindrucksvoll die beinahe geniale Einfachheit, die sich in FORTH in fast allen Bereichen wiederfindet. Der Compiler muß nicht zwischen Doppelpunktdefinitionen, Variablen, Konstanten oder Feldern unterscheiden können. Jedes Wort wird durch den Adreßinterpreter auf die selbe Weise aufgerufen. Wie sich ein Wort später verhält, wird, wie oben beschrieben, über die durch das Codefeld adressierte Maschinenroutine festgelegt. Die Vorteile liegen auf der Hand. Der Aufbau des Compilers ist einfach (in der Regel nicht umfangreicher als zehn Zeilen FORTH Kode), der Compiler ist jederzeit um beliebige Datentypen erweiterbar.
Bliebe noch die Bedeutung des Daten-bzw. - um im FORTH-Jargon zu bleiben — Parameterfeldes zu klären. Das Parameterfeld enthält die Daten, mit denen ein FORTH-Wort arbeiten muß. Im Falle einer Doppelpunktdefinition enthält das Parameterfeld die Adressen (genauer gesagt die Codefeldadressen oder kurz Cfa’s) der einzelnen Komponentenworte. Wird nun eine Doppelpunktdefinition zur Ausführung gebracht, sorgt CALL dafür, daß die einzelnen Komponentenworte nacheinander über ihre Cfa’s zur Ausführung gebracht werden. Da diese Komponentenworte wiederum aus (Unter-) Komponentenworten zusammengesetzt sein können, und sich der ganze Vorgang dann eine Ebene „tiefer“ wiederholt, ist es sinnvoll, eine Rückkehradresse zu speichern. Diese Adresse, über ein Wort wieder in die rufende Ebene zurückgekehrt, wird auf dem Return Stack abgelegt, wodurch sich auch die Bezeichnung für diesen Stack erklärt.
Daß es sich bei den Adressen der Komponentenworte tatsächlich um die Codefeldadressen der einzelnen Wörter handelt, läßt sich mit Hilfe des Wortes ’ (tick) nachprüfen. ’ wird in der Form < Name > aufgerufen und bringt die Codefeldadresse von Name auf den Stack.
Immediate Worte bilden eine Ausnahme
Beendet wird eine Doppelpunktdefinition durch ; (Semikolon). ; wird bereits in der Definitionsphase ausgeführt und kompiliert die Codefeldadresse seiner Laufzeitroutine EXIT in das Parameterfeld von SUMME. Wie kommt es aber, daß ; ausgeführt wird, obwohl sich das System doch noch im Compilemodus befindet und ; eigentlich in das Wörterbuch kompiliert werden müßte? Die Lösung ist einfach. ; gehört zu der Gruppe der sog. Immediate Wörter. Diese Wörter werden auch während des Compilemodus d. h. auch innerhalb einer Doppelpunktdefinition direkt ausgeführt.
Woran erkennt der Compiler, ob es sich bei einem Wort um ein Immediate Wort handelt? Diese Information ist in Form eines einzelnen Bits im ersten Byte des Namensfeldes eines Wortes enthalten. Ist dieses sog. „Precedence“ Bit gesetzt, so handelt es sich bei dem betreffenden Wort um ein Immediate Wort. Die Verarbeitung von Immediate Worten ist ein weiteres eindrucksvolles Beispiel dafür, mit welchen einfachen Mitteln der FORTH Compiler gesteuert wird. Trifft der Textinterpreter im Compilationsmodus auf ein Wort im Eingabedatenstrom, so entscheidet das Precedence Bit darüber, ob die Codefeldadresse des Wortes in das Wörterbuch eingetragen, oder ob das Wort direkt ausgeführt wird.
Es sei an dieser Stelle angemerkt, daß diese Methode den Compiler zu steuern noch wesentlich ausbaufähiger ist. Gerade in 32 Bit Systemen steht viel Platz für zusätzliche Kontroll- und Statusbits zur Verfügung, die mit in den Wortnamen aufgenommen werden können. So wäre es z. B. denkbar, ein weiteres Bit einzuführen, welches darüber Auskunft gibt, ob ein Wort nur innerhalb einer Doppelpunktdefinition eingesetzt werden darf.
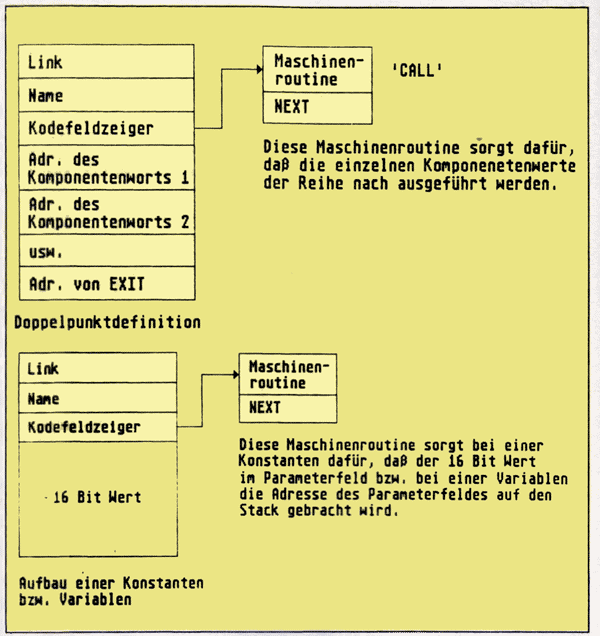
Auch eine Variable - bzw. Konstantendefinition entspricht dem allgemeinen Schema aus Abb. 1, allerdings mit zwei Unterschieden. Zum einen besteht das Parameterfeld lediglich aus dem 16 Bit Wert der Variablen bzw. der Konstanten. Zum anderen zeigt das Codefeld eines durch VARIABLE definierten Wortes auf eine Maschinenroutine, die dafür sorgt, daß bei Aufruf dieses Wortes die Parameterfeldadresse auf den Stack gebracht wird. Genauso zeigt das Codefeld eines durch CONSTANT definierten Wortes auf eine Maschinenroutine, die dafür sorgt, daß bei Aufruf des betreffenden Wortes der im Parameterfeld gespeicherte Wert auf den Stack gebracht wird. Jede dieser Maschinenroutinen endet übrigens mit einem Sprung zum Adreßinterpreter (NEXT), der in der nächsten Folge etwas ausführlicher vorgestellt wird. Abb. 3 zeigt den allgemeinen Aufbau eines durch :, CONSTANT bzw. VARIABLE definierten Wortes.
Wir haben nun drei verschiedene Definitionsworte kennengelernt. Die Worte, die durch diese Definitionswörter definiert werden, weisen allesamt einen sehr ähnlichen Aufbau auf (siehe auch Abb. 3). Lediglich das Verhalten beim Aufruf dieser Worte ist recht unterschiedlich. Halten wir fest: Dieser Unterschied liegt in dem unterschiedlichen Codefeldinhalt begründet. Jedes FORTH-Wort (egal durch welches Definitionswort es definiert wurde) besitzt die gleiche Struktur und wird einheitlich aufgerufen. Lediglich die Größe des Parameterfeldes kann variieren. Anders als in typischen Compilersprachen wie C oder PASCAL findet strenge Typenunterscheidung statt. Genauso wenig sind Datentypen festgelegt. Eine FORTH Variable, die zur Speicherung von Integerzahlen vorgesehen ist, kann ohne weiteres auch zur Speicherung von Fließkommazahlen oder Zeichenketten eingesetzt werden. Der Adreßinterpreter, der in FORTH die Ausführung eines Wortes übernimmt, „weiß“ also gar nicht, was für eine Art von Wort als nächstes zur Ausführung gelangt. Dieser einheitliche Aufruf ist eine der wenigen Dogmas, die ein FORTH Programmierer nicht umstoßen darf, wenn er nicht den Charakter des Systems grundlegend verändern will. Hat man dieses Prinzip erst einmal verstanden, so eröffnen sich vollkommen neue Möglichkeiten, die in Sprachen wie C oder PASCAL nicht einmal annäherungsweise mit der gleichen Leichtigkeit erreicht werden können.
Definitionsworte selber definiert
So ist es z. B. ohne großen Aufwand möglich Definitionsworte selber zu definieren. Dazu muß aber zunächst ein wenig näher auf das Verhalten eines Definitionswortes eingegangen werden. Die Definition eines neuen Wortes durch ein Definitionswort läuft in drei Phasen ab, die zum besseren Verständnis am Beispiel des Definitionswortes CONSTANT erläutert werden:
1. Phase: Definition des Definitionswortes CONSTANT
: CONSTANT
CREATE
'
; CODE
Maschinenkode
Sprung zu NEXT
Auch ein Definitionswort muß irgendwann einmal definiert werden. (Definitionsworte wie :, CONSTANT und VARIABLE sind bereits im Sprachkern enthalten) Zentraler Bestandteil eines jeden Definitionswortes ist CREATE. Es wird in der Form CREATE < Name > aufgerufen und erzeugt einen Wörterbucheintrag für Name, der aus Namens-, Verbindungs- und Codefeld besteht. Der Codefeldzeiger zeigt zunächst auf die gleiche Routine, wie der Codefeldzeiger, eines durch VARIABLE definierten Wortes. Somit verhält sich ein durch CREATE definiertes Wort zunächst wie eine Variable. Anschließend wird der Wert n, der sich noch im Stack befindet, durch , (komma) in das Parameterfeld von Name eingetragen. Die Definition von , ist neu und soll an dieser Stelle einmal nachgeholt werden. , wird in der Form n, aufgerufen und trägt die Zahl n an der nächsten freien Adresse im Wörterbuch ein (jene Adresse, die durch den Wörterbuchzeiger DP adressiert wird). Da CREATE dafür sorgt, daß der Wörterbuchzeiger auf das Parameterfeld des soeben definierten Wortes zeigt, wird der Wert genau dort eingetragen. Bliebe noch die Funktion von ; CODE zu klären. Auch hierbei handelt es sich um ein Immediate Wort, welches noch innerhalb der Definitionsphase ausgeführt wird. Es trägt die Codefeldadresse seiner Laufzeit Prozedur (;CODE) in das Parameterfeld von CONSTANT ein. Später bei der Ausführung von CONSTANT hat (;CODE) die Aufgabe, einen Zeiger auf die nachfolgende Maschinenroutine in das Codefeld des durch CONSTANT zu definierenden Wortes einzutragen. Nach ;CODE folgt jene Maschinenroutine, von der bereits mehrmals die Rede war, und die für das Verhalten eines durch CONSTANT definierten Wortes bei seiner Ausführung verantwortlich ist.
Während der Definitionsphase eines Definitionswortes wird sowohl das Verhalten des Definitionswortes bei seiner Ausführung, als auch das Verhalten der durch das Definitionswort zu definierenden Worte bei deren Ausführung festgelegt.
2. Phase: Das Definitionswort tritt in Aktion
Bsp. 11 CONSTANT WERT
Zunächst wird für WERT ein Wörterbucheintrag erzeugt (durch CREATE) und anschließend die Zahl 11 in das Parameterfeld von WERT (durch ,) eingetragen. Zusätzlich wird in das Codefeld von WERT ein Zeiger auf die Maschinenkoderoutine am Ende von CONSTANT eingetragen, (dafür sorgt (;CODE) )
3. Phase: Das definierte Wort tritt in Aktion
WERT ok
Beim Aufruf von WERT wird der Inhalt des Parameterfeldes, nämlich die Zahl 11, auf den Stack gebracht. Diese Aufgabe übernimmt die Maschinenkoderoutine, die durch das Codefeld von WERT (oder allgemein, aller durch CONSTANT definierten Worte) adressiert wird.
Nicht immer ist es erforderlich, das Verhalten eines Definitionswortes in Maschinenkode zu definieren. Immer dann, wenn eine möglichst weitgehende maschinenunabhängigkeit erreicht werden soll, ist es sinnvoll, unter Inkaufnahme eines geringen Zeitverlustes, Definitionsworte ausschließlich in Hochkode zu definieren. Dies geschieht in FORTH mit Hilfe der Konstruktion 'CREATE...DOES > ’, die in folgender Form aufgerufen wird:
: DEFINITIONSWORT
CREATE < Anweisungen1 >
DOES > < Anweisungen2 >
;
DEFINITION SW ORT ist der Name des zu definierenden Definitionswortes, Anweisungen 1 sind die Worte, die beim Aufruf des Definitionswortes zur Ausführung kommen, während Anweisungen die Worte darstellt, die beim Aufruf eines mit Hilfe des Definitionswortes definierten, Wortes zur Ausführung gelangen. Damit Sie vor lauter Definitionsworten und Definitionen nicht ganz den Überblick verlieren, wird auch DOES> an einem anschaulichen Beispiel vorgestellt.
Ein in Lehrbüchern gern verwendetes Beispiel ist die Definition eines Definitionswortes für Feldvariablen, da im FORTH-83 Standard keine Feldtypen definiert sind. Was liegt näher, als die Definition eines Definitionswortes zur Definition von Feldern nachzuholen. Das Definitionswort soll ARRAY heißen und in der Form
n ARRAY <Name>
aufgerufen werden, wobei n die Größe des (eindimensionalen) Feldes festgelegt und Name den Namen der Feld-variablen darstellt. Wie auch im letzten Beispiel müssen bei der Definition eines Definitionswortes zwei Dinge festgelegt werden:
- Das Ausführungsverhalten von ARRAY
- Das Ausführungsverhalten der durch ARRAY definierten Worte
Abb. 4 zeigt den möglichen Aufbau eines Definitionswortes ARRAY. Gehen wir den Aufbau von ARRAY einmal Wort für Wort durch. Zunächst wird für Name ein Wörterbucheintrag erzeugt. In das Parameterfeld wird der Wert n eingetragen. Dies ist zwar nicht unbedingt erforderlich, kann aber für spätere Erweiterungen (z. B. einer Indexbereichsüberprüfung) ganz nützlich sein. ALLOT sorgt dafür, daß in dem zu definierenden Wort für 2 ★ n Bytes Platz geschaffen wird. Damit wäre das Ausführungsverhalten von ARRAY festgelegt. Nach DOES> folgt nun jener FORTEI Kode, der das Ausführungsverhalten von Name festlegt.

DOES > sorgt zunächst einmal dafür, daß bei Aufruf von Name, dessen Parameterfeldadresse auf den Stack gebracht wird. Ausgehend von dieser Adresse gilt es nun, die effektive Adresse des gewünschten Index zu berechnen. So muß z. B. beim Aufruf von 3 <Name> die Adresse des 3. In-dices auf den Stack gebracht werden. Dazu wird durch SWAP die Adresse des Parameterfeldes von Name und der Indice auf dem Stack vertauscht. Der Index wird mit zwei multipliziert, da das Feld zur Aufnahme von 16 Bit Zahlen dienen soll. Der resultierende Offset wird zur Startadresse des Feldes, die sich ja noch auf dem Stack befindet, addiert, woraus die effektive Adresse des 3. Indices resultiert.
Bsp. 10 ARRAY FELD ok
(es wird ein Feld mit dem Namen FELD zur Aufnahme von max. zehn 16 Bit Werten definiert)
0 FELD U. 36154 ok
Adresse des 0. Indices.
(Unter dieser Adresse ist die bei der Definition von FELD angegeben max. Anzahl von Indices angegeben, die in FELD untergebracht werden können. Trotzdem können Sie auch ohne weiteres einen Index angeben, der aus diesem Rahmen herausfällt. So wird z. B. die Abspeicherung einer geraden Zahl unter einem Index von -1 das Codefeld von FELD zerstören und das System bei erneutem Aufrufen von FELD zum Absturz bringen).
1 FELD U. 36156 ok
Adresse des 1. Indices
2. FELD U. 36158 ok
Adresse des 2. Indices usw.
Wie wird nun mit einer Feldvariablen gearbeitet? Im Prinzip genauso, wie mit einer einfachen Variablen. So wird z. B. durch die Sequenz
123 4 FELD ! ok
die Zahl 123 an die vierte Stelle im Feld eingetragen. Dieser Wert kann durch Ausführung von
4 FELD @ . 123 ok
wieder ausgegeben werden.
Die Konstruktion ’CREATE...DOES > ’ stellt eine leistungsfähige Methode dar, in FORTH Definitionsworte zu definieren. Durch ’CREATE ... DOES>’ lassen sich nicht nur Datentypen definieren, sondern auch vollkommen neue Wortstrukturen. Auf diese Weise lassen sich Sprachelemente z. B. zur Verarbeitung von Listen oder zur objektorientierten Programmierung definieren, die FORTH LISP oder SMALLTALK ähnliche Eigenschaften verleihen und so FORTH auch als Implementationssprache für manche KI Anwendungen interessant machen.
In der nächsten Folge soll gezeigt werden, daß FORTH auch nach „unten“ erweiterbar ist. So lassen sich Maschinenkoderoutinen problemlos in FORTH Hochkode einbinden. Zu den typischen Anwendungen gehört die Programmierung zeitkritischer Routinen, die Einbindung von Betriebssystemroutinen aber auch die Steuerung von Peripheriegeräten z. B. über den ST-Userport.