
Vom Papier zur Datenbank: Die elementaren Datenbankbefehle
Hallo! Ich begrüße Sie zum zweiten Teil des Programmierkurses. Die heutige Folge beschäftigt sich mit den wichtigsten Befehlen zum Arbeiten mit Relationen. Ich erwähnte bereits in der Einleitung, daß ich nur auf zwei Systeme eingehe, dBMAN und STandard BASE. Dies hat folgende Gründe:
Beide Programme orientieren sich stark (STBASE sogar 100%) nach dem Standard-Datenbanksystem dBASE III für PC’s. Während meiner Ausbildungszeit (DV-Kaufmann) habe ich damit intensiv gearbeitet und mich sehr dafür begeistert.
ADIMENS hingegen ist zwar auch eine relationale Datenbank, die aber in der Programmierung und Bedienung erheblich von den oben genannten abweicht. Außerdem meine ich, ist sie nicht so flexibel gestaltbar und eher für Endbenutzer als für Programmierer konzipiert. Mit der Sprache ADITALK (siehe Test ST-Computer 3/88) erhielt ADIMENS eine ‘Query-Language’ (Abfragesprache) sowie die Möglichkeit, den Verarbeitungsablauf über Schleifen und Bedingungen zu steuern. Vielleicht werde ich für spätere Folgen bei entsprechendem Interesse und Resonanz dieses Programm mit in den Kursus einbeziehen.
Soviel dazu und zum Thema: ich beschreibe die Befehle, um mit Hilfe des Datenbanksystems (DBMS = DATA BASE MANAGEMENT SYSTEM) Dateien aufzubauen.
Ich werde sie verständlicherweise nicht in allen Einzelheiten ausführen, denn ich will ja keine Kopie der Handbücher schreiben. Mein Kurs soll Ihnen den Einstieg in die relationale Welt Schritt für Schritt erleichtern. Um alle Fähigkeiten des Systems auszunutzen, müssen Sie auf die vollständige Befehls-Syntax in den Handbüchern zurückgreifen.
Der nun folgende Teil ist in fünf Abschnitte gegliedert:
a) die Umsetzung der Relationen in eine Struktur (Aufbau einer Tabelle), sowie deren ggfs, später notwendige Modifikation
b) Erfassen von Daten,
c) Abrufen (Anzeigen und Suchen) von Informationen,
d) Änderungen vornehmen,
e) Daten löschen
Startet das Datenbankprogramm mit einem Doppelclick auf dem entsprechenden Symbol. Es meldet sich dann der Prompt (bei dBMAN in der obersten Zeile CMD:, STBASE richtet sich nach dem großen Vorbild).
Vorsicht!
Das Programm muß IMMER mit einem QUIT verlassen werden. Nur so ist sichergestellt, daß alle Daten, die sich noch im Rechner befinden, auf Disk zurückgeschrieben werden. Falls Sie einfach einen Reset machen, um ins Desktop zurückzugelangen, könnte ein völliger Datenverlust die Folge sein, weil die Dateien nicht sauber geschlossen werden. Das gilt auch für bereits bestehende Files, weil u.U. der Datei-Ende-Pointer (EOF) nicht richtig gesetzt wird. Beide Systeme erlauben drei Betriebsarten: zum einen den Kommando-Modus, in dem man sich nach dem Start des Programms befindet (erkennbar am Prompt). Alle eingegebenen Befehle werden sofort interpretiert, ausgeführt und Ergebnisse am Bildschirm protokolliert.
Im Programmier-Modus steht ein Full-Screen Editor zur Verfügung. Es können richtige Programme geschrieben werden. Doch dazu im übernächsten Teil des Kurses mehr. In der dritten Betriebsart, vergleichbar mit ‘RUN’ beim BASIC, übernimmt eine erstellte Programmlogik die Steuerung des Verarbeitungsablaufs.
Schaffe, schaffe, Häusle baue...
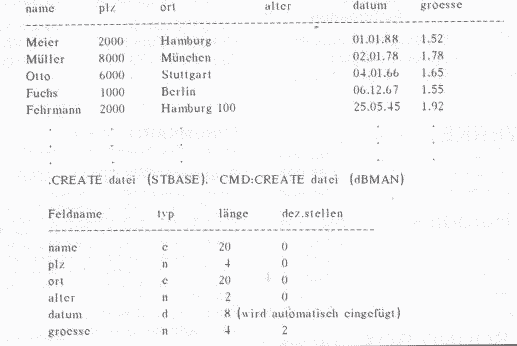
Hier sollen natürlich keine Häuser, sondern Tabellen geschaffen (kreiert) werden. Abbildung 1 zeigt eine Relation, die in eine dem Computer verständliche Form umgesetzt werden soll. Ich werde mich auf dieses Beispiel, welches nur als Testobjekt dient, des öfteren beziehen. Der Befehl, mit dem Relationen in Ihrer Struktur definiert werden, lautet: CREATE name < RETURN > (Anmerkung: ich schreibe aus dem Grund der Übersichtlichkeit alle Schlüsselwörter in Großbuchstaben; es ist aber nicht nötig, denn das System erkennt auch Kleinbuchstaben. STBASE bietet die Möglichkeit, alle Schlüsselwörter mit ihrer Kurzschreibweise zu verwenden, d.h. nur die ersten vier Buchstaben reichen aus).
Mit (name) gibt man der Tabelle einen Namen. Unter dieser Bezeichnung wird die Datei auf der Disk gespeichert und unterliegt so den TOS-Konventionen (Buchstaben und Ziffern, max. 8-stellig). Die Extension darf nicht mit angegeben werden; sie lautet immer .dbf (data base file, in Anlehnung an dBASE III). Der Tabellenname muß einmalig vergeben werden und darf nicht bei einer weiteren Relation des gleichen Anwendungsgebietes verwendet werden, weil sonst die alte überschrieben wird (Beispiel für gültige Namen: DISK, PROGRAMM, TEST1). Das erscheint logisch, da in einem Diskverzeichnis nicht zweimal der gleiche File-Name auftreten kann.
| name | plz | ort | alter | datum | groesse |
|---|---|---|---|---|---|
| Meier | 2000 | Hamburg | 01.01.88 | 1.52 | |
| Müller | 8000 | München | 02.01.78 | 1.78 | |
| Otto | 6000 | Stuttgart | 04.01.66 | 1.65 | |
| Fuchs | 1000 | Berlin | 06.12.67 | 1.55 | |
| Fehrmann | 2000 | Hamburg 100 | 25.05.45 | 1.92 |
Abb. 1: Beispieltabelle
Das DBMS stellt daraufhin eine Erfassungsmaske auf dem Bildschirm zur Verfügung, die sich in vier Spalten aufteilt. Mit der < RETURN >-Taste bewegt man sich zur jeweils nächsten Kolumne.
a) Feldname: Jede Domäne einer Tabelle muß einen Feldnamen erhalten, der in einer Relation einmalig sein muß; in einer anderen kann er aber erneut vergeben werden. Die Namenskonvention von Feldern: bis zu 10 Zeichen; erstes Zeichen muß ein Buchstabe sein, danach können Ziffern folgen, auch der Unterstrich (_) ist erlaubt (Beispiel: DISK_NR, ANREDE). Mit diesem Namen erfolgt der Zugriff auf die Feldinhalte.
b) Feldtyp: Er bestimmt, welche Art von Informationen die Felder dieser Spalte beinhalten werden.
Das System bietet eine Vielzahl von Möglichkeiten an.
C- alphanumerisches Feld (z.B. für Namen, Anschriften)
N- numerisches Feld, mit dem gerechnet werden soll
D- Datumsfeld. Das System enthält spezielle Kalenderfunktionen, mit denen Datumsangaben behandelt werden (Prüfung auf Gültigkeit, Vergleiche, usw.), z.B. wird bei der Eingabe der 29.02.87 abgelehnt, weil es ein ungültiges Datum ist.
Es gibt noch weitere Typen, die aber selten benutzt werden bzw. durch andere ersetzbar sind (z.B. logische Felder) und deshalb hier nicht beschrieben werden sollen. Die genannten vier Typen decken fast alle Aufgabengebiete ab.
c) Länge: sie gibt die Breite des Feldes an. Es muß die Gesamtlänge eingegeben werden, z.B. muß bei einer dreistelligen Zahl mit zwei Nachkommastellen hier eine sechs (6) eingetragen werden.
Bei Datumsfeldern (Typ D) ist hier keine Angabe nötig; die Länge wird automatisch nach Drücken von < RETURN > auf 8 vorgegeben.
d) Nachkommastellen: Für numerische Felder kann optional eine Stellenzahl nach dem Komma erfaßt werden. Diese kommt in das vierte Feld der Erfassungsmaske.
Sind alle Felder beschrieben, beendet man mit CTRL-S den Aufbau. Die Datei, deren Strukturdefinition in Abbildung (2) wiedergegeben ist, steht nun zur Verfügung.
Mit dem Befehl USE name eröffnet man die Tabelle zur Bearbeitung. Falls es erforderlich wird, sich später diese festgelegte Struktur der Datei anzuschauen, so kann der Aufbau mit LIST STRUCTURE oder LIST STRU (STBASE) angezeigt werden. Stellt man fest, daß die Tabelle in ihrer Struktur geändert werden muß (z.B. Feldlänge zu klein. Hinzufügen weiterer Felder. Löschen von Feldern, Umbennung von Feldnamen usw.) ermöglicht MODIFY STRUCTURE oder MODI STRU die nachträgliche Änderung des Dateiaufbaus. Dabei gehen bereits erfaßte Informationen nicht verloren, es sei denn, man entfernt oder verkleinert Felder.
Das DBMS legt zur Strukturänderung eine Kopie der Datei an, ändert das Original und kopiert dann aus der Zwischendatei die Daten zurück. Die Änderungen können in der bereits bekannten Maske vorgenommen werden.
Das Erfassen von Daten
Für die Benutzer von dBMAN gilt: Das Datumsformat ist grundsätzlich in der Schreibweise MM/TT/JJ. Da dies in Deutschland nicht üblich ist, muß in die Kommando-Zeile SET DATE TO 1 eingegeben werden, um die “normale” Form (TT/MM/JJ) zu erhalten. Besonders bei Eingaben ist dieser Punkt wichtig, weil das System sonst beharrlich z.B. den 25.01.88 ablehnt (es interpretiert daraus nämlich einen 25. Monat, den es ja nicht gibt).
Bei STBASE braucht keine Angabe gemacht zu werden (das System ‘schluckt’ zwar den Befehl SET DATE GERMAN; er ist aber ohne Wirkung). Die Datumseingabe geschieht in deutschem Format; leider wird es umgekehrt abgespeichert (MM/TT/JJ). Zum Aufnehmen neuer Informationen stehen zwei Befehle bereit. Zum einen kann man an beliebigen Stellen Datensätze einfügen (INSERT, nur bei STBASE) oder an das Ende neue Tupel anfügen (APPEND). Da unsere Beispieltabelle noch leer ist, benutzen wir den APPEND-Befehl und schreiben einfach in die Kommandozeile APPEND und erfassen so den ersten Datensatz der Tabelle mit Hilfe einer Ediermaske. Links befinden sich die Datenfeldbezeichnungen. rechts die Eingabefelder.
Man merkt, daß in numerisch definierte Felder nur Ziffern eingegeben werden können. Bei Dezimalzahlen erscheint stellengerecht das Komma (als Punkt). Das System überprüft automatisch die eingegebenen Daten auf Gültigkeit und erspart so dem Programmierer die umständliche Codierung von Plausiblitätskontrollen. Sogar Datumsangaben werden kontrolliert und logisch falsche Eingaben abgewiesen.
Wir füllen, um Testdaten für folgende Übungen vorzubereiten, die Datei mit ca. 30 Phantasiedaten. Lassen Sie bitte das Feld ‘alter’ noch leer; es wird zur Verdeutlichung eines anderen Befehls im ‘jungfräulichen’ Zustand benötigt.
Innerhalb der Erfassungsmaske können die Cursor-Tasten zum Edieren benutzt werden. Nach der Eingabe des letzten Feldes eines Satzes erscheint sofort eine neue, leere Maske (bei dB MAN muß CTRL-N gedrückt werden).
Sollen keine weiteren Daten erfaßt werden, so drückt man nach Erfassung des letzten Satzes CTRL-S. Es meldet sich dann der Prompt des Systems wieder.
Zum Verständnis: das System führt intern einen Zeiger, der auf den aktuellen Datensatz verweist (Datensatznummer). Will man zwischen den ersten und zweiten Satz einen neuen einfügen, so schreibt man GO 1 und anschließend INSERT. Mit dem GO-Befehl setzt man den Datensatzzeiger auf einen ganz bestimmten Satz. Jeder Satz ist so einzeln ansprechbar. GO TOP setzt den Zeiger auf den ersten, GO BOTTOM auf den letzten Satz der Tabelle. Mit SKIP n bewegt man sich relativ zur aktuellen Position. Ist n positiv, so springt man Richtung Datei-Ende, sonst zum Anfang. So gelangt man mit SKIP 1 zum nächsten Satz (hier könnte die ‘ 1 ’ weggelassen werden); mit SKIP -2 setzt man den Zeiger auf den vorvorletzten Datensatz. In der internen Variablen RECNO() ist dieser Zeiger gespeichert. Anzeigen mit: ? RECNO() (Das Fragezeichen ist ja wohl vom BASIC her als PRINT -Befehl hinlänglich bekannt !!) Mit dem INSERT werden die Datensatznummern der folgenden Zeilen jeweils um 1 erhöht. Der Befehl kann auch mit dem Zusatz BEFORE versehen sein. Dann erfolgt die Einfügung vor der aktuellen Zeile.
Das Abrufen von Informationen
Am LIST bzw. LOCATE-Befehl erkennt man deutlich den descriptiven Charakter der Sprache. Die Formulierung kommt der Umgangssprache sehr nahe. Mit GO TOP und anschließend LIST ALL werden alle Datensätze gelistet (ei, wer hätte das gedacht ?). Ganz links vor jeder Zeile steht die Nummer, unter der der Satz gespeichert ist. Sie kann mit der Erweiterung LIST OFF ALL unterdrückt werden.
Sind in der Tabelle viele Sätze gespeichert, so scrollen sie schnell über den Bildschirm. Der DISPLAY-Befehl verhindert das Scrollen und stoppt die Ausgabe nach einer Seite und wartet auf einen Tastendruck zum Weitermachen (DISPLAY ALL).
ALL gibt den Bereich an. der gezeigt werden soll. Möglich wäre auch ein LIST NEXT 5, welches die nächsten fünf Sätze ab der aktuellen Position listet, sofern vorhanden.
Dies ist aber nur die einfachste Form der Anwendung. Man kann Bedingungen stellen und so einzelne Sätze selektiv herausgreifen. Möchte man alle Personen des Wohnortes Hamburg, so schreibt man LIST ALL FOR ort = ‘Hamburg’ zum Anzeigen ausgewählter Datensätze. (< ort > ist der Feldname !) Als Vergleichsoperatoren sind erlaubt: < > =, sowie deren Kombinationen (<>, >=, <=). Die Operationen sind für alle vier genannten Feldtypen erlaubt, sogar bei Datumsfeldern: LIST ALL FOR datum > CTOD (’02.01.77') Die Funktion CTOD bedeutet ‘character to date’ und wandelt ein alphanumerisches Feld in den Typ ‘Datum’ um. Der Inhalt bleibt derselbe. Andernfalls könnte die Operation nicht ausgeführt werden, da stets auf beiden Seiten die Datentypen übereinstimmen müssen. Ein numerisches Feld kann z.B. auch nicht mit ‘ABC’ verknüpft werden. Das DBMS stellt aber für alle Fälle die nötigen Umwandlungsfunktionen bereit:
STR(alter,n) wandelt numerisch in alphanumerisch mit der Feldlänge n.
DTOC(datum) Datum nach Character
VAL(name) konvertiert String in Zahlen, beginnend von links. Beim Auftreten von Buchstaben bricht die Funktion ab, Beispiel: VAL(’12AB’) ergibt 12
Leider (s.o.) sind bei STBASE die Datumsfelder im Monat und Tag vertauscht gespeichert. So wird aus dem 02.01.77 der 1. Februar und nicht der 2. Januar. Darauf müßen Sie achten! Es ist möglich, auch auf Teile eines Feldes zuzugreifen. Der Substring-Operator $ ermöglicht die Suche eines Teilstrings innerhalb eines bestimmten Feldes.
LIST ALL FOR ‘burg’$ort Diese Anweisung sucht alle Orte, in denen ‘bürg’ vorkommt. Dabei ist es unerheblich, an welcher Stelle sich diese Kombination befindet. Man findet also ‘Hamburg’ wie auch ‘Hamburg 100’. Die Ausgabe über Drucker ist mit dem Zusatz ‘TO PRINT’ möglich.
Sollen die Datensätze nicht alle nacheinander, sondern einzeln ausgegeben werden, so bietet sich der Befehl LOCATE an. Er ist in der Wirkungsweise ähnlich wie LIST, bleibt jedoch nach dem ersten zutreffenden Datensatz stehen, der dann mit DISPLAY angezeigt werden kann. Mit CONTINUE wird die Suche fortgesetzt. LOCATE ALL FOR ‘A’ $name Ein folgender DISPLAY zeigt den gefundenen Datensatz an. Einzelne Felder sind über ihren Feldnamen abrufbar: ? ort oder ? DTOC(datum) (Datumsfelder können ohne Umwandlung s.o. nicht angezeigt werden!)
Änderungen
Daten unterliegen ständigen Änderungen, sei es, daß Falscheingaben korrigiert oder alte Daten an aktuelle Werte angepaßt werden müssen.
Die Datenbanksysteme bieten mit dem Befehl EDIT bzw. REPLACE die Möglichkeit, bestehende Daten mit neuen Werten zu überschreiben. Dazu muß der Datensatzzeiger auf den zu ändernden Satz gestellt werden, z.B. GO 5. Man kann aber auch einfacher schreiben EDIT 5 Damit wird die Maske (wie bei APPEND) angezeigt, in der die alten Daten modifizierbar sind.
Mit dem REPLACE-Befehl können einzelne Felder sofort geändert werden, ohne die Maske anzuzeigen. Dies ist besonders später in Programmen nötig.
So erfolgt mit GO 5 und anschließendem REPLACE name WITH 'Egon Müller’ die Änderung des Namens im fünften Satz. Wie bei allen anderen Befehlen kann die Verarbeitung auf mehrere Sätze gleichzeitig wirken:
REPLACE ALL alter WITH YEAR(DATE())-YEAR(datum)
Wow, das ist ein Ausdruck! Er ersetzt alle Felder, in denen das Alter steht (zunächst noch leer, s.o.) mit dem errechneten aktuellen Alter. Und das geht so:
- DATE() enthält das Systemdatum
- die Funktion YEAR(...) ermittelt das Jahr aus einem Datum
Vom heutigen Jahr wird also das Geburtsjahr abgezogen und in das Feld ‘alter’ gestellt. Dies geschieht bei allen Datensätzen !! Mit LIST ALL kann anschließend das Ergebnis kontrolliert werden.
Löschen (Ja/Nein)???
Soll einzelner Satz aus einer Tabelle entfernt werden, benutzt man DELETE, womit der aktuelle Satz gelöscht wird - nein, noch nicht endgültig. Er kann mit RECALL wieder zum Leben erweckt werden. Soll die Löschung aber tatsächlich durchgeführt werden, so muß nach dem DELETE ein PACK folgen, damit die fortlaufende Datensatznumerierung wieder in eine kontinuierlich aufsteigende Reihenfolge gebracht wird. Löschen wir nämlich aus einer Tabelle mit 5 Sätzen den ersten, so müssen die übrigen eine neue Nummer erhalten (1...4).
Der ‘DELETE’ markiert lediglich die Datensätze mit einem Zeichen (*), daß sie zum Löschen vorbereitet sind. Um diese Sätze von der weiteren Verarbeitung auszuschließen, formuliert man SET DELETED ON. Dann werden mit LIST ALL die markierten Sätze nicht mehr mit ausgedruckt. SET DELETED OFF behandelt die markierten Zeilen, als wären sie nicht gelöscht.
Um alle Sätze einer Relation zu löschen, könnte man z.B. so Vorgehen DELETE ALL und PACK. Dieser Vorgang würde aber recht lange dauern, da erst jeder Satz zum Löschen markiert und anschließend physisch auf der Disk entfernt werden müßte. Eleganter und sehr viel schneller ar-beit der ZAP. Er löscht in einem Arbeitsgang (nach einer Sicherheitsabfrage) alle Sätze einer Datei, nicht jedoch die Struktur!
So, das waren die grundsätzlichen Befehle, um mit einer Relation zu arbeiten. Es dürfte Ihnen nun nicht mehr schwerfallen, die Tabellen des ersten Teils zu codieren (mit CRE-ATE) und anschließend mit Daten zu füllen. Probieren Sie es doch einfach aus. Beachten Sie aber bitte:
Bevor Sie die Arbeit mit dem Datenbanksystem beenden, vergessen Sie das KWITT nicht!!!
Schwester, bitte Skapell!!
Ich sprach im ersten Teil von Mengen- und Relationenoperationen, auf die ich noch kurz eingehen möchte, a) Mengenoperationen beziehen sich immer auf die gesamte Tabelle. Als Beispiel nenne ich den SUM-Befehl, der die Summe aller Feldinhalte einer numerischen Domäne ermittelt (hier: Berechnung des Gesamtalters aller Personen). Das Ergebnis wird auf dem Bildschirm angezeigt.
SUM alter - Die Ausführung dieses Befehls kann von Bedingungen (FOR) anhängig gemacht werden (siehe LIST).
Ein weiterer Befehl, der die Tabelle als Einheit betrachtet, ist COUNT. Er zählt alle Datensätze; auch in Verbindung mit FOR, z.B. COUNT FOR name = ‘Meier’ ermittelt, wieviele Personen unter diesem Namen erfaßt sind.
Ein ‘ganz toller’ Befehl ist SORT. Mit dessen Hilfe kann eine gesamte Datei nach bestimmten Feldern auf- oder absteigend sortiert werden. Als Standardwert gilt eine aufsteigende Sortierfolge:
SORT ON name TO temp Einfach, oder ? Das klingt doch echt wie normale Sprache. Programmieren Sie so etwas mal in BASIC oder C !!!
Die nach Namen sortierte Datei ist in der Tabelle temp gespeichert. Mit USE temp und LIST ALL können wir uns das Ergebnis betrachten. Leider erzeugt ein SORT eine sortierte Kopie der alten Datei. Dies kann bei großen Datenmengen zu Engpässen führen (besonders auf Disketten). Auch ist die Tabelle immer nur unmittelbar nach dem SORT in richtiger Reihenfolge. Nachträgliche Änderungen erfordern grundsätzlich eine Neusortierung.
In der nächsten Ausgabe werde ich eine elegantere Form der Sortierung beschreiben, das Indizieren. Hierbei werden neu eingegebene Sätze sofort in die richtige Reihenfolge gebracht, b) Relationenoperationen ermöglichen die gezielte Auswahl von Zeilen und Spalten. Die Sicht auf eine Tabelle wird eingeschränkt; die Datei erscheint kleiner, obwohl mehr Sätze bzw. Felder gespeichert sind.
LIST name,ort zeigt aus der Relation nur die angegebenen Felder. Die anderen Spalten sind nicht erreichbar. SET FILTER TO plz = 8000 und LIST ALL (Der Vergleichsoperator darf hier nicht in Hochkommata eingeschlossen sein, weil es sich um ein numerisches Feld handelt!) Mit dieser Anweisung werden nur noch die Personen aus München betrachtet. Die Tabelle ist scheinbar geschrumpft, denn selbst mit LIST ALL
werden nicht alle gespeicherten Sätze gelistet. Der Filter blendet also Zeilen aus und kann auch auf mehrere Spalten gleichzeitig wirken (mit einer logischen UND-Verknüpfung)
SET FILTER TO plz = 8000 .and. datum = CTOD(’01.01.77')
(Merke: das Setzen eines neuen Filters hebt die vorherige Wirkung wieder auf) Wenn ich schon dabei bin: Folgende logische Operationen sind möglich:
.NOT. nicht .AND. und .OR. oder Sie können nicht nur beim Filtern, sondern auch beim LIST, LOCATE und DELETE verwendet werden, um die Verarbeitung von Bedingungen abhängig zu machen.
Ein SET FILTER TO ohne Parameter stellt den ursprünglichen normalen Zustand her. Übrigens, wenn Sie die dauernden Systemmeldungen stören, dann stellen Sie sie doch einfach ab. Dann werden aber auch Ergebnisse (z.B. COUNT, SUM) nicht mehr angezeigt.
SET TALK OFF Das will ich jetzt auch tun und beende damit den zweiten Teil. Hoffentlich habt Ihr anhand ausgesuchter Beispiele die Leistungsfähigkeit des DBMS erkannt. Gerade bei der Verarbeitung von riesigen Datenmengen macht sich der Einsatz in einer enormen Arbeitserleichterung bemerkbar.
Freut Sie sich schon auf die nächste Ausgabe. Denn da geht ganz fix die Post ab mit Sortierung und Datensuche.
Paul Fischer
Quellen: dBASE III Das relationale Datenbanksystem für 16-Bit- Computer. Autor: Dr. Peter Albrecht, Verlag: Markt und Technik
Paul Fischer