
Vom Papier zur Datenbank: Das Indizieren von Datenbanken
In dieser Folge beschäftige ich mich mit einem höchst interessanten Thema: das Arbeiten mit indizierten Datenbanken. Zuerst will ich Ihnen aber das Verwalten von mehreren Tabellen erklären, denn eine einzelne Relation ist noch keine Datenbank. Gerade das gleichzeitige Zusammenspiel und die Organisation mehrerer verschiedener Relationen kennzeichnet die Leistungsfähigkeit eines Datenbanksystems.
Das Arbeiten mit mehreren Dateien
Sie haben hoffentlich mittlerweile eine Relation aufgebaut. Um mit der Datei zu arbeiten, benutzt man “USE datei”. Das sollte aus dem letzten Teil noch bekannt sein. Erinnert Sie sich bitte auch an den Datensatzzeiger, der stets auf die aktuelle Datensatznummer verweist.
Diese Nummer ist ja bekanntlich über die Variable RECNO() abrufbar. Befindet sich der Zeiger ganz am Anfang der Tabelle (noch vor dem ersten Datensatz), so wird gleichzeitig die logische Variable (Schalter) BOF() wahr, d.h. ihr Zustand ist TRUE. Für das Dateiende gibt es den Schalter EOF(), der durch seinen logischen Wert TRUE auf das Ende der Relation hinweist, d.h. es sind keine weiteren Sätze enthalten. EOF() wird erst nach dem Lesen des letzten Satzes wahr. Diese Variablen sind besonders bei er Programmierung wichtig, damit ein Programm nicht mit einer Fehlermeldung abbricht, weil z.B. über das Dateiende gelesen wurde (Bild 1 zeigt den Zusammenhang).
Unmittelbar nach einem USE befindet sich der Zeiger immer am Anfang der Tabelle (auf dem ersten Datensatz). Wenn nun eine zweite Datei mit USE eröffnet wird, so “vergißt” das System die vorherige Datensatznummer (z.B. 10) und springt an den Dateianfang der neuen Tabelle. Die erste Datei wird automatisch geschlossen, die Satznummer des zuletzt bearbeiteten Satzes geht verloren. Soll auf diese Relation erneut zugegriffen werden, so muß es mit USE erfolgen.
Dieser Zustand ist durchaus ärgerlich. Will man nämlich die erste Datei sequentiell abarbeiten (z.B. Stammdaten) und mit Daten aus einer zweiten Tabelle (z.B. Bewegungsdaten) aktualisieren (mischen), so müßte man sich immer die Datensatznummer der Stammdatei Zwischenspeichern, um nach dem Wechseln zur Bewegungsdatei den nächsten Datensatz zu finden.
Doch ein Datenbanksystem läßt hier die Programmierer nicht im Regen stehen. Mit SELECT können Dateiarbeitsbereiche gewechselt werden, ohne die Datensatznummer der Tabellen zu verlieren. Das System übernimmt die Zwischenspeicherung von bis zu zehn Dateien gleichzeitig.
Die Syntax bei STBASE ist genau wie bei dBASE III. Die Dateien werden von 1 -10 (auch weniger möglich) durchnumeriert. Der erstmalige Aufruf von z.B. zwei Tabellen (Eröffnen) erfolgt dann mit
SELECT1
USE datei1 SELECT 2
USE datei2
Bei dBMAN sind die Datein nicht mit Ziffern gekennzeichnet, sondern mit den Buchstaben J bis S mit einem vorangestellten F (für File). So eröffnet man zwei Dateien
SELECT FJ
USE datei1
SELECT FK
USE datei2
Nun kann durch einen SELECT der Datei-Arbeitsbereich in eine andere Relation verlegt werden, ohne die Datensatznummer der ersten Datei zu verlieren (“dateil” ist die primäre, “datei2” die sekundäre Datei). Mit einem einfachen
SELECT 2 bzw. SELECT FJ
springt man in die zweite Relation.
Will man zur ersten zuriickkehren, so geschieht es mit SELECT 1 bzw. SELECT FJ Man befindet sich dann auf der Datensatznummer, die zuletzt in diesem Arbeitsbereich bearbeitet wurde. Es können nur Felder der jeweils “aktiven” Relation angesprochen werden! Die “inaktive” Datei wird aber nicht geschlossen.
Ein Beispiel soll dies verdeutlichen. In einer Tabelle sind Namen und Anschriften (PLZ und Straße) gespeichert. Aufgrund der Normalisierung sind die Ortsnamen in einer zweiten Relation abgelegt, die über die Postleitzahl erreichbar sind. Zum Drucken von z.B. Adreßaufklebem muß die Adreßdatei sequentiell gelesen werden. Nach jeder Anschrift muß dann die zweite Tabelle zum Bestimmen des Ortes nachgelesen werden. Anschließend wird der nächste Name verarbeitet. Durch einfache SELECT-Anweisungen kann zwischen den Dateien hin- und hergeschaltet werden. Besonders für die Anschriftendatei ist es wichtig zu wissen, welcher Name als letzter verarbeitet wurde, damit keine Anschrift zweifach gedruckt wird.

Die Verwendung von Variablen
Eigentlich gehört dieses Thema erst in den vierten Teil, in dem das Erstellen von Programmabläufen beschrieben wird. Doch es bietet sich an, die Benutzung von Variablen hier schon aufzuführen, z.B. um Feldinhalte zwischenzuspeichem oder Ergebnisse von Operationen (z.B. SUM, COUNT) nicht auf dem Bildschirm auszugeben, sondern in Variablen abzulegen (COUNT ALL TO summe).
Es gibt wie bei den Feldtypen verschiedene Arten von Variablen (numerische, alphanumerische, Datums- und logische Variablen). Durch die Initialisierung wird der Typ festgelegt. Für Variablen sollten selbstsprechende Namen vergeben werden, z.B. ort, telefon. Bei mir hat es sich bewährt, um die Speichernamen von Feldbezeichungen leichter zu unterscheiden, als ersten Buchstaben ein “m” bzw. für Dateifelder ein “f” zu wählen. Hat man z.B. eine Relation mit dem Feld “fname” und will dieses Zwischenspeichern, so lautet die Variable “mname”. Die Zuweisung erfolgt wie in BASIC mit dem Gleichheitszeichen:
mname = fname (z.B. alphanumerisch )
mdatum = DATEI) (z.B. Datum)
malter = falter (z.B. numerisch)
Das liest sich zwar etwas komisch, aber wenn man das Prinzip verstanden hat, ist es durchaus brauchbar. Achtung! Vor dem ersten Benutzen der Variablen sollten sie bereits definiert sein (z.B. summe = 0. COUNT ALL TO summe).
Die Funktionen zum Umwandeln der Typen (z.B. numerisch in alphanumerisch) habe ich schon im zweiten Teil des Kurses beschrieben. Hierzu noch ein paar Ergänzungen.
Mit numerischen Variablen können alle vier Grundrechenarten ausgeführt werden. Die Syntax ist denkbar einfach: siehe BASIC. Komplizierte Funktionen (Sinus. Cosinus) gibt es nicht. Das liegt daran, daß Datenbanksysteme hauptsächlich im kaufmännischen Bereich verwendet werden, wo weniger Berechnungen, sondern eher Speicher- und Wiederauffindprobleme eine Rolle spielen.
Bei dem Arbeiten mit Datumsangaben und alphanumerischen Variablen ist zu beachten, daß das System generell zwischen diesen Typen unterscheidet, auch wenn es scheint, als hätten Datumsfelder den Charakter alphanumerischer Variablen. So meckert der Interpreter beharrlich folgenden Ausdruck an:
DATE()+’ abc’ (das Plus verbindet Strings, siehe BASIC)
Man kann also keine Felder dieser Typen verknüpfen. Erst die Umwandlung mit
? DTOC(DATE())+’abc’
bringt ein gültiges Ergebnis. Versuchen Sie doch einmal, diese Nuß zu knacken:
mjahr=STR(VAL($(DTOC(DATE()),7,2))-18,2)
Wenn Sie diesen Ausdruck nachvollziehen können (eigentlich ist hier nichts Unbekanntes enthalten), haben Sie wohl alles verstanden (das Beipiel zeigt übrigens deutlich die Leistungsfähigkeit des Parsers)!!
Logische Variablen kennen nur zwei Zustände: wahr oder falsch. Sie können also auch als eine Art Schalter aufgefaßt werden. Weitere Hinweise sind aus Bild 1 ersichtlich. Da diese Variablen fast ausschließlich der Steuerung von Programmen dienen, werde ich im vierten Teil ausführlicher darauf eingehen. Sie sind hier nur der Vollständigkeit halber erwähnt.

Das Indizieren
Nach diesem kleinen mathematischen Exkurs nun wieder zurück zu den Relationen. Im zweiten Teil sprach ich die Nachteile der Sortierung bereits an (die ich nicht wiederholen will).
Mit dem INDEX ON .. TO .. werden die Schwächen des SORT-Befehls umgangen.
Als Übungsobjekt verwenden Sie am besten die Beispielrelation des zweiten Teils. Rufen Sie sie mit “USE datei” auf. Gehen wir nach dem Motto “Learning By Doing” vor. Soll die Tabelle nach Namen sortiert werden, schreiben Sie
INDEX ON nenne TO index1
(index 1) ist der Name der Indexdatei, die durch den Befehl erzeugt wird. Da diese auf Diskette geschrieben wird, unterliegt sie den bekannten TOS-Konventionen. Eine Extension darf auch hier nicht angegeben werden; sie lautet vom System her .ndx (Index). Je nach Größe der Ausgangsdatei dauert es eine Weile, bis sich der Prompt wieder meldet.
Diese Datei ist ebenfalls eine Relation! Sie enthält aber immer nur zwei Felder, und zwar das Schlüsselfeld (hier: name=feld1) und die Nummer des entsprechenden Datensatzes der Ausgangsdatei (feld2). Für jeden Satz der zu indizierenden Datei wird ein Satz in die Indexdatei geschrieben. Das erledigt das System automatisch. Bild(2+3) zeigt die Tabelle “datei”, die nach Namen indiziert wurde, mit der zugehörigen Indexdatei. Diese Indexdatei kann nicht mit “USE index1” benutzt werden. Der Befehl lautet etwas anders. Mit
USE datei INDEX index1 DISPLAY ALL
kann anschließend das Ergebnis betrachtet werden. Die Tabelle ist nach Namen aufsteigend sortiert.
“Bis hierhin unterscheidet sich eine Indizierung nicht von einer Sortierung” könnte nun einer sagen. Stimmt. Nein! Doch nicht !!
Was bringt uns das?
Erstens: Werden in eine indizierte Datei neue Datensätze aufgenommen, so bringt das System sie sofort an die richtige Position, d.h. eine mit “USE ... INDEX “ geöffnete Datei ist immer in der richtigen Reihenfolge. Beim SORT würde ein Hinzufügen oder Ändern des Sortierfeldes immer einen neuen SORT erfordern. Probieren Sie es aus, indem Sie mit APPEND neue Namen anfügen und anschließend LISTen.
Zweitens: Eine Tabelle kann nach mehreren Feldern indiziert werden, z.B. könnte unsere Datei gleichzeitig auch nach “datum” sortiert sein. INDEX ON datum to index2 (index2) enthält nun die aufsteigende Reihenfolge des Datums. Die Erstellung von sortierten Geburtstagslisten wird durch die Möglichkeit der Indizierung von Datumsfeldern ein Kinderspiel.

Sind für eine Relation mehrere Indizes angelegt, sollten auch beim Eröffnen alle Indexdateien angegeben werden (durch Komma getrennt), um Änderungen der Schlüsselfelder auch in den Indexdateien vom System verwalten zu lassen. Die erstgenannte Indexdatei gibt dann stets die aktuelle Sortierung vor. Alles kapiert??
USE datei INDEX indexl ,index2
Wenn unsere Tabelle mit diesem Befehl eröffnet wird, zeigt ein DISPLAY ALL eine nach Namen sortierte Relation. Werden neue Datensätze aufgenommen, so kommen sie immer in die richtige Reihenfolge. Auch die Reihenfolge des zweiten Index wird vom System mitgepflegt.
SET INDEX TO index2 DISPLAY ALL
wechselt in die zweite Indexdatei und zeigt dieselben Datensätze, nur in einer anderen Sortierung. Das erstaunliche ist, daß das System die komplette Pflege der Indizes übernimmt, solange die entsprechenden Indexdateien beim Eröffnen (USE ... INDEX) mit angegeben wurden.
Drittens: Ich erwähnte im ersten Teil schon einmal den Begriff zusammengesetzter Schlüssel bzw. Kombinationsschlüssel. So können in der Anwendung des INDEX auch zusammengesetzte Felder (oder nur Teile eines Feldes mit Hilfe der Substring-Funktion) zur Indizierung benutzt werden. Dabei ist zu beachten, daß zusammengesetzte Schlüsselfelder immer den gleichen Typ haben (eine Verknüpfung von “name” und "groesse” wäre nur über Umwege möglich). Soll z.B. eine Sortierung nach Ort und innerhalb eines Ortes nach Namen erfolgen, lautet der Befehl (die Verknüpfung erfolgt mit einem simplen Pluszeichen)
INDEX ON ort+name TO index3
Mit “USE datei INDEX index3, index1,index2" kann das Ergebnis der Operation betrachtet werden. Die Datei ist primär nach Orten sortiert. Innerhalb des Ortes sind die Namen in aufsteigender Reihenfolge. Ist eine absteigende Sortierung gewünscht -kein Problem, INDEX ON ... TO ... DESCENDING erledigt auch dieses Problem.
Viertens: Die Suche nach bestimmten Datensätzen wird enorm beschleunigt (klar, in einer sortierten Datei sind effizientere Suchalgorithmen möglich). Dazu muß die Datei nach dem Schlüssel indiziert werden. Nehmen wir obiges Beispiel
USE datei INDEX indexl ,index2 ,index3 Nun haben wir eine nach Namen sortierte Relation (hoffentlich ist alles gutgegangen!!). Soll nun eine schnelle Suche nach einem bestimmten Namen (z.B. Müller) erfolgen, reicht es zu schreiben
mname = ‘Müller’
SEEK mname
Mit dem SEEK kann eine nach diesem Feld indizierte Datei sehr rasant durchsucht werden. DISPLAY zeigt dann den gefundenen Satz an. Bei Kombinationsschlüsseln müssen natürlich beide Felder angegeben werden:
SET INDEX TO index3 mort = ‘Hamburg’ mname = ‘Meier’ SEEK mort+mname
In (feld2) sind nur die Datensatznummern der zugehörigen Datensätze gespeichert. Das System durchsucht mit SEEK die sortierte Relation und kann bei Bedarf mit Hilfe des Inhalts aus (feld2) auf den kompletten Datensatz zugreifen.
Fünftens: Die Benutzung des INDEX hilft, die so gefürchteten Datenredundanzen so gering wie möglich zu halten. Ein SORT erzeugt generell eine komplette Kopie der zu sortierenden Datei. Bei mehreren Sortierfolgen entstehen Redundanzen; gleiche Daten sind mehrfach gespeichert. INDEX generiert immer nur eine Teilkopie der Tabelle, so daß nur der Schlüssel doppelt vorhanden ist.
Sechstens: Mit der Benutzung von Indextabellen wird der langsame LOCATE-Befehl fast zu den Akten gelegt. Bei dem Verwalten von sehr vielen Datensätzen macht sich der Geschwindigkeitsvorteil des SEEK erheblich bemerkbar. Auch die automatische Pflege des Index spricht für den Einsatz der Indizierung.
Trotzdem wird LOCATE weiterhin benötigt. Ist eine Tabelle nach einer Domäne indiziert, wobei deren Feldinhalte nicht eindeutig sind (z.B. nur die Indizierung des Nachnamens), so kann man mit SEEK zunächst nur den ersten treffenden Datensatz (bezogen auf den Schlüssel) finden; eine weitere Auswahl des gewünschten Namens geschieht dann mit LOCATE .. FOR ..
Worauf muß geachtet werden ?
Ich erwähnte oben die automatische Indexpflege des Systems. Diese kann jedoch nur dann funktionieren, wenn bei der Eröffnung der Datenbank alle zugehörigen Indextabellen mit angegeben werden. Wird dies versäumt, so stimmt die Ausgangsdatei nach Änderungen (REPLACE. APPEND, DELETE, ZAP) nicht mehr mit der entsprechenden Indextabelle überein (das System erkennt diesen Unterschied). Um beide Dateien miteinander abzustimmen, gibt es die REIN-DEX-Anweisung, von der ich aber abraten möchte.
Da der INDEX ... TO ... sehr schnell arbeitet, bietet es sich an, die “alte” Indexdatei zu löschen und eine neue aufzubauen. Um Dateien auf der Diskette zu löschen, schreibt man
DELETE FILE datei.ext (ext . = dbf oder ndx)
Vor dem Löschen erfolgt eine Sicherheitsabfrage, damit nicht versehentlich wichtige Informationen verloren gehen. Achtung! Haben Sie “SET TALK OFF” aktiv (gilt nur für STBASE, denn bei dBMAN ist im Kommando-Modus immer TALK ON geschaltet), so wird die Datei sofort entfernt!
Weiterhin muß beachtet werden: eine indizierte Relation befindet sich logisch in einer anderen Reihenfolge. Deshalb ist nicht gewährleistet, daß mit "GO 1" der Dateianfang gefunden wird. Man sollte bei indizierten Tabellen auf die Befehle GO TOP bzw. GO BOTTOM ausweichen, die stets an die Grenzen der Datei gelangen, unabhängig von der Datensatznummer.
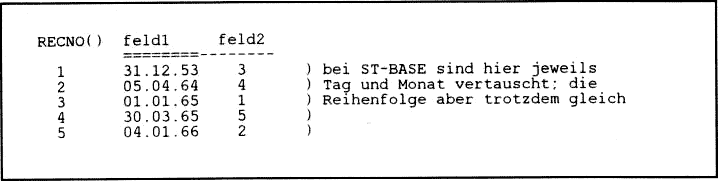
Als '"Hausaufgabe” möchte ich Ihnen folgende Aufgabe stellen: Es ist möglich. Datumsfelder zu indizieren. Doch leider ist das Ergebnis als "Geburtstagsliste” nicht so brauchbar. da das älteste Datum (31.12.53) an erster und das neueste Damm an letzter Stelle (z.B. 04.01.66) steht (Bild 41. Eine Geburtstagsliste müßte vielmehr nach Monat und innerhalb des Monats nach Tagen indiziert sein. Versuchen Sie einmal, den Befehl für eine solche Indiziemng zu formulieren! Auflösung, siehe vierten Teil.

Wie geht’s weiter ?
Im vierten und letzten Teil werde ich eine allgemeine Einführung in die strukturierte Programmierung geben, weil die Elemente der “eingebauten” Programmiersprache zu einer solchen zwingen. Anhand ausgewählter Beispiele zeige ich die Syntax einiger wichtiger und häufig verwendeter Anweisungen im speziellen (Schleifen, Abfragen, Ein/-Ausgabe) und beschreibe den generellen Aufbau von Programmen. Am Ende werden Sie hoffentlich auch eine ähnliche Begeisterung für relationale Datenbanksysteme entwickeln wie ich.
Paul Fischer