
Algorithmen und Datenstrukturen in PASCAL Teil 3 : Listen
Nachdem wir uns in den beiden ersten Folgen von Algorithmen & Datenstrukturen mit zwei Strukturen zur Datenanordnung (Stacks und Queues) beschäftigt habe, möchte ich heute mit der Datenverarbeitung beginnen. Geplant sind hier insgesamt drei Unterkapitel, in denen ich mich von den heute behandelten Listen, über allgemeine Binär-Bäume, zu den AVL-Bäumen vorarbeiten werde.
Motivation
Nach dieser kurzen Übersicht, möchte ich zunächst die Motivation für Nachfolgendes geben. Da die Datenerfassung und Verarbeitung unbestritten eine der Hauptaufgaben des Computers ist, stellt sich die Gretchenfrage:
Wie sollen Daten erfaßt und verarbeitet werden?
Dazu gibt es, wie sich aus der Einleitung ablesen läßt, viele Ansätze, die aber immer zwei Gemeinsamkeiten haben:
- Zunächst wird in allen diesen Problemlösungen eine Struktur vereinbart (Liste, Baum, ...).
- Nach der Festlegung der Struktur , müßen hier Daten, in einer gewissen Abfolge, eingeordnet werden. Es muß also ein Kriterium (Schlüssel) aus den Daten ausgewählt werden, nach dem die Einordnung erfolgen kann.
Schlüssel
Mit diesen Schlüsseln möchte ich mich zunächst etwas näher befassen.
Die einzige Forderung an Schlüssel sind, daß sie sich anordnen laßen, das heißt es existiert eine <, oder <= - Relation, mittels der eine Einordnung in die Struktur erfolgen kann.
In PASCAL trifft dies auf alle einfachen Datentypen, in Zusammenhang mit der 'normalen' <, bzw. <= - Relation, zu:
- integer, real, char
- string (soweit vorhanden)
- boolean (obwohl das etwas arm wirkt : FALSE<TRUE)
- sämtliche Aufzählungs- und Unterbereichstypen
Natürlich ist es auch möglich sich selbst auf anderen Datentypen eine Relation zu definieren. Als Beispiel möchte ich hier Vektoren nennen, die üblicherweise folgendermaßen dargestellt werden:
. CONST dim = 10; . TYPE vektor_type = ARRAY [1..dim] OF real; . VAR vektor : vektor_type; .
Hieraus kann man einen Schlüssel und somit eine Relation konstruieren, indem man die Länge des Vektors betrachtet :
FUNCTION relation(v1, v2: vektor_type) : boolean;
FUNCTION laenge (v : vektor_type) : real;
VAR i : integer; help : real;
BEGIN {laenge}
help:=0;
FOR i:=1 TO dim DO
help:=help+v[i]*v[i];
laenge:=sqrt(help);
END; {laenge}
BEGIN {relation}
relation:=laenge(v1)<=laenge(v2);
END; {relation}
(Nichtmathematiker sollte dieses Beispiel nicht abschrecken, es ist für die weitere Betrachtung von keinerlei Bedeutung.)
Angeordnete Listen
Ausgerüstet mit diesem Schlüsselbegriff, kann man nun die Anforderungen an unsere Liste wie folgt definieren:
- Zunächst Zerfallen sämtliche, zu erfassenden, Daten in einen Schlüssel (key) und in restliche Daten (data). (Beispiel: Adressen Zerfallen in Nachnamen (key) und Restadressen (data))
- Gemäß diesem Schlüssel wird ein Datensatz (key & data) so in die Liste eingeordnet, daß sämtliche Datensätze der Vorgänger <= dem neuen Datensatz sind, und umgekehrt sämtliche Nachfolger >= dem Datensatz sind.
- Um diese Struktur zu unterhalten, werden folgende Operationen benötigt:
- create : Zum Initialisieren einer Liste.
2. insert : Zum Einfügen eines Elementes in eine bestehende Liste.
3. delete : Zum Löschen eines durch einen Schlüssel bezeichne ten Elementes.
Weiterhin muß man Daten natürlich wiederfinden können, dazu die beiden Operatorenpaare:
4a. find_first : Liefert das erste Listenelement mit bezeichnendem Schlüssel.
4b. find_next : Liefert das jeweils nächste Element.
5a. first : Liefert das generell erste Listenelement.
5b. next : Liefert das jeweils nächste Element.
Und 'last but not least': Was nutzt uns das Ganze, wenn wir es nicht speichern können:
6. save : Speichert eine komplette Liste.
7. load : Lädt eine komplette Liste.
Zeigercharakter
Wie schon zweimal, werde ich auch hier zur Realisierung wieder die dynamische Speicherverwaltung bemühen. Betrachten Sie hierzu bitte Listing 3a:
Ein Listenelement (list_element) besteht nun, wie man sieht, zunächst aus einem Schlüssel (key von key_type) und Restdaten (data von data_type). key_type und data_type sind nun, unter Beachtung der im Punkte Schlüssel genannten Einschränkungen, frei wählbar. Der Einfachkeit halber habe ich beide zu Integer gewählt.
Der dritte Bestandteil eines Listenelementes ist nun ein Zeiger auf das nachfolgende Listenelement. Die etwas verwirrende Typbezeichnung list für den Listennachfolger, liegt darin begründet, daß der Listenkopf, also der Zeiger, der den Anfang der Liste markiert (Und somit synonym für die komplette Liste steht), ebenfalls nur ein Zeiger auf list_element ist.
Als letztes benötigt ich noch einen Typ für den Datentransfer zwischen der Liste und der Datei, in der die Daten zu speichern sind (file_type). Da man mit dem Zeiger in der Datei nichts anfangen kann, besteht dieser Dateidatentyp nur aus key_type und data_type.
Mit diesen Datentypen realisieren sich nun unsere neun Operationen (Listing 3b) folgendermaßen:
- create(X)
Hier ist nichts weiter zu tun, als die Liste zu nil zu initialisieren.
- insert(new_key,new_data,x)
Das Einfügen in eine Liste gestaltet sich in drei Schritten:
- Erzeugung des nötigen Speichers (new).
- Initialisierung des neuen Elementes (key, data).
- Das Einhängen in die Liste, was den komplizierteren, der drei, Vorgänge darstellt.
Hier sind drei Fälle zu unterscheiden (Abb. 3a).
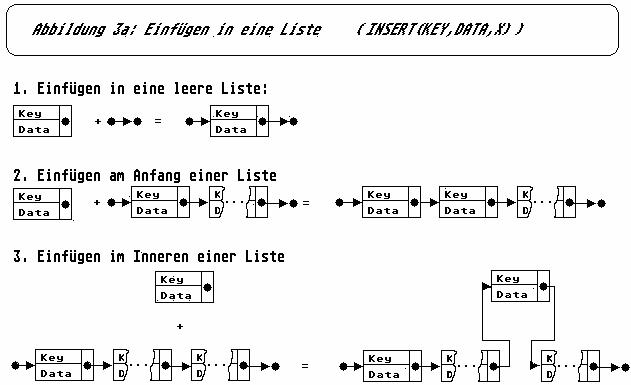
Zunächst besteht die Möglichkeit, daß die Liste noch leer ist (x=nil). In diesem Fall ist das einzufügende Element selbst die Liste und der Nachfolger dieses Elementes wird zu nil. Bei nicht leeren Listen (else-Zweig) ist nun wieder die Unterscheidung zu treffen, ob am Anfang der Liste eingefügt werden soll, oder im Inneren (IF key<=x^.key THEN). Am Anfang einzufügen ist nun wieder der einfache Fall. Der Nachfolger des neuen Elementes (next) ist dann die Liste und die Liste beginnt mit dem neuen Element (x:=new_element). Im anderen Fall ist nun die Liste zu durchlaufen. Dazu wird ein Hilfszeiger (work_ptr) benutzt, der zunächst auf x zeigt. Die Liste wird nun solange durchlaufen, bis entweder das Listenende erreicht ist, oder ein passender Schlüssel gefunden wurde. Wichtig hierbei ist, daß man immer vorausschauend abprüft, also immer den Schlüssel des Nachfolgers (work^.next^.key) betrachtet.
Um diese Notwendigkeit einzusehen, betrachten Sie bitte den dritten Fall der Abbildung 3a. Wie Sie sehen, müßen zum Einfügen eines Elementes in eine Liste sowohl der Zeiger work_ptr^.next, als auch der next-Zeiger des neuen Elementes umgesetzt werden. Würde die Liste nicht voraus-schauend durchlaufen, so könnte man work_ptr^.next nicht mehr umsetzen, weil man schon damit beim nächsten Element angelangt wäre.
Wenn bis zum Ende der Liste noch nicht eingefügt wurde (IF NOT fertig), so ist das neue Element das letzte Listenelement und die Zeiger müßen entsprechend umgesetzt werden.
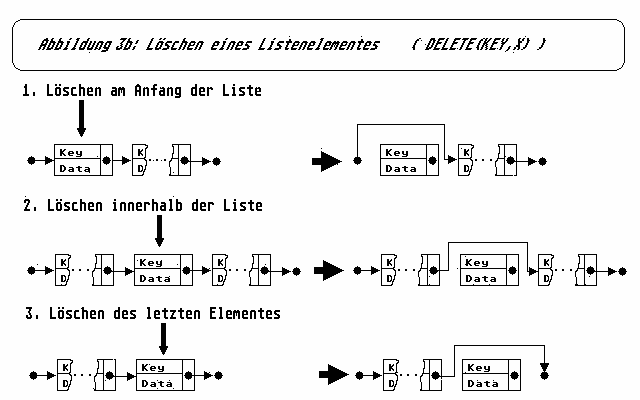
- delete(key,x)
Bei der Löschoperation delete(key,x) müßen nun zwei Fälle unterschieden werden.
Beim Löschen am Anfang der Liste muß durch Umsetzen des Listenzeigers auf seinen eigenen Nachfolger, das erste Element ausgefügt werden. Auch beim Löschen innerhalb der Liste ergibt sich nun wieder, wie schon bei insert, die Notwendigkeit die Liste vorausschauend zu durchlaufen. Deswegen hat die hierzu notwendige Konstruktion (WHILE ... DO) eine gewisse Ähnlichkeit mit der Konstruktion bei insert. (Sie unterscheiden sich nur in den Zeigerumsetzungen.) Da bei delete nun noch die Möglichkeit besteht, daß der Ausfügevorgang fehlschlägt (kein Element mit Schlüssel key), muß der Erfolg, oder Mißerfolg, des Ausfügevorgangs dem aufrufendem Programm noch mitgeteilt werden. Aus diesem Grund ist delete eine Funktion mit Ergebnisparameter boolean.
Ein weiteres Problem von delete besteht darin, daß bei den bisherigen Definitionen davon ausgegangen wurde, daß auch doppelte Schlüsselbelegungen, also beispielsweise zweimal der Schlüßel >1<, möglich sind. Da bei delete aber nur der jeweils erste Eintrag mit Schlüssel key gelöscht wird, ist es erforderlich, durch wiederholten Aufruf von delete, sämtliche Einträge zu entfernen, wenn dies erwünscht ist. Die erforderliche PROCEDURE ist im Modul selbst nicht formuliert, könnte aber folgendermaßen aussehen:
PROCEDURE delete_keys( key : key_type; VAR x : list);
BEGIN {delete_keys}
WHILE delete(key,x) DO ;
END; {delete_keys}
- find_first(x,key,data) und find_next(key,data)
Um nun Informationen aus einer Liste x zu bekommen, muß es möglich sein, in dieser Liste nach bestimmten Schlüsseln zu suchen. Diese Aufgabe kommt dem Funktionspaar find_first und find_next zu. Ihre Arbeitsweise hat man sich so vorzustellen, daß die Funktion find_first den ersten Datensatz der Liste mit Schlüssel key liefert und find_next, nacheinander, sämtliche weiteren Datensätze berechnet.
Benutzt wird hierzu eine Hilfsfunktion find und eine globale Variable akt_find. find hat nun die Aufgabe die Liste ab der Position akt_find zu durchsuchen. Dazu wird die Liste mit dem Arbeitszeiger akt_find durchlaufen (WHILE ...), bis das Ende erreicht ist, oder ein key entsprechender, Datensatz gefunden wurde.
Bei find_first ist nun nur noch zu beachten, daß vor dem Aufruf von find der Zeiger akt_find mit dem Listenkopf initialisiert wird. find_next, schließlich, begnügt sich mit dem Aufruf von find.
Bei beiden Funktionen ist nun noch zu beachten, daß der Funktionswert jeweils die Gültigkeit des Datensatzes angibt. Dies bedeutet, beide Funktionen liefern einen gültigen Wert, wenn der Funktionsaufruf true ergibt, sowie einen undefinierten Wert, sonst.
- first(x,key,data) und next(key,data)
Bei diesen beiden Funktionen handelt es sich um eine abgemagerte Variante der vorherigen Funktionen. Es wird nicht nach einem bestimmten Schlüssel gesucht, sondern es wird das jeweils nächste Listenelement einer Liste x komplett (Schlüssel & Restdaten) ausgegeben.
Dazu wird ebenfalls wieder eine globale Variable akt_list benötigt, die die bis jetzt erreichte Stelle in der Liste x markiert. Die Arbeitsweise ist klar:
Bei first wird zunächst ein Check auf eine gefüllte Liste durchgeführt (gefunden:=x<>nil). Liegt eine gefüllte Liste vor (IF ... THEN), so kann man die Rückgabewerte belegen (key, data). Der Zeiger akt_list bekommt dabei den Wert von x, da ja gerade das erste Element untersucht wurde. Der FUNCTION first muß nun nur noch der Rückgabeparameter gefunden mitgeteilt werden.
next, schließlich funktioniert völlig analog, nur das man hier nicht die Liste, die beim Zeiger x beginnt, betrachtet sondern die Liste, die beim Zeiger akt_list beginnt, also die Restliste.
Problematik dieser beiden Funktionen, wie schon der Funktionen unter 4, ist die Tatsache, daß globale Variablen benutzt werden. Wenn man nun, wie ich, die FUNCTIONen/PROCEDUREn als Header-File vereinbart (siehe auch Testumgebung, Listing 3c), so ist es, wegen der etwas restriktiven PASCAL-Syntax, erforderlich, das Modul der Listenoperationen (Listing 3b) zuerst zu benennen.
Begründung: In PASCAL dürfen Variablen und Funktions-/Procedure- Deklarationen nicht gemischt werden (anders, als z.B. in C).
- save(x,filename)
Da die Bedeutung dieses Befehls wohl klar sein dürfte, komme ich gleich zur Programmierung:
Was Sie hier sehen, ist eine typische Anwendung der beiden vorhergehenden Funktionen first und next. Nach der schreibenden Öffnung, der durch filename bezeichneten Datei, werden zunächst mit first, später mit next, die Schlüssel und die Restdatendefinitionen in den Dateipuffer t geschrieben und später mit put(t) in die Datei filename selbst befördert.
- load(x,filename)
Auch beim Laden von Listen, kann man eine Anwendung von zwei anderen Listenoperationen wiederfinden, nämlich die Anwendung von create(X) und insert(key,data,x). Ähnlich wie bei save, wird hier auch zunächst die Datei mit Namen filename eröffnet, diesmal allerdings mit lesendem Zugriff. Nach der Initialisierung, der zu ladenden Liste (create(x)), erfolgt der Aufbau der Liste mittels insert(key,data,x). Dazu wird die Pufferinformation der Datei (key & data) in die Liste x eingefügt.
Testumgebung
Nachdem ich oben, wie ich hoffe in ausreichendem Umfang, auf die Programmierung von Listen eingegangen bin, möchte ich nun auf die Anwendung der Listenoperationen zu sprechen kommen.
Dazu habe ich eine kleine Testumgebung für die Module geschrieben (Listing 3c). Hier wird eine Liste mit den oben beschriebenen Operationen verwaltet, das heißt es ist möglich eine Liste, Auf- und Abzubauen, sie nach bestimmten Kriterien, oder auch ohne Kriterien, zu Durchsuchen, sie zu Speichern und wieder zu Laden.
Bei der Programmierung ist zunächst der Deklarationsteil interessant. Man sieht als erstes den Aufruf der Typvereinbarungen durch $I. Die Variablenvereinbarung beinhaltet nun hauptsächlich die Deklaration der Liste (x : list;), sowie die Deklaration zweier Hilfsvariablen schluessel und daten. Mit der Variable frage wird die Benutzereingabe vorgenommen und in str kann ein Dateiname eingelesen werden. Auf die Variablendeklaration erfolgt nun sofort (siehe auch Anmerkung unter 5.) der Aufruf des Moduls list.pas (Dieses enthält unsere Listenoperationen und die beiden globalen Variablen).
Im Anweisungsteil erfolgt nun nichts erstaunliches mehr. Nach der Initialisierung unserer Schlange x mit create, wird eine REPEAT-Schleife, zwecks Wiederholung des Benutzerdialoges, betreten. Nach der Ausgabe eines Kommandomenüs und der Wahl einer entsprechenden Funktion, erfolgt die Abarbeitung der Funktion ganz im Sinne der oben definierten Listenoperationen. Bemerkenswert ist hier vielleicht noch das Zusammenwirken von first und next, bzw. find_first und find_next bei dem Auflisten sämtlicher Elemente einer Liste, bzw. dem Auflisten sämtlicher Elemente mit gleichem Schlüssel (Menüpunkte <3> und <4>).
 Vorausschau
Vorausschau
Nach dem glücklichen Abschluß der Listen, werde ich mich nun, in der nächsten Folge von Algorithmen & Datenstrukturen, auf Binär-Bäume stürzen. Sie stellen eine weitere Struktur zur Datenverarbeitung dar und sind in gewissem Sinne optimaler als Listen, wenn man ihre Einfüge- und Suchzeiten vergleicht. Doch dazu später mehr.
Für heute möchte ich mich bei Ihnen für Ihr Interesse bedanken und erwarte unser Wiedersehen im nächsten Monat.
Dirk Brockhaus